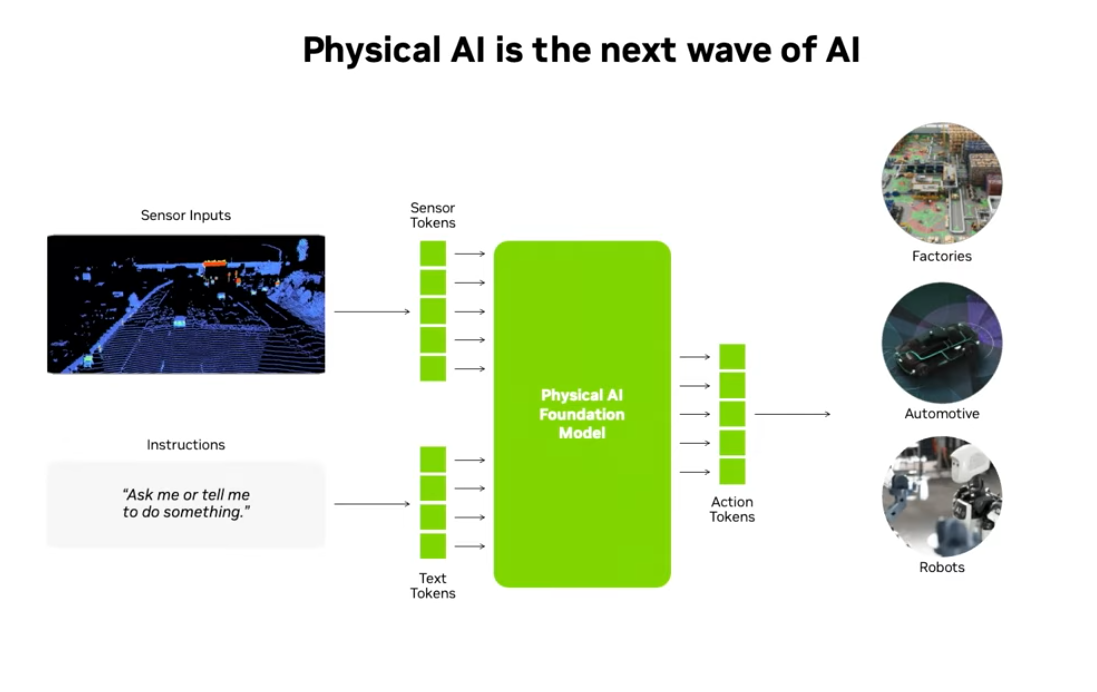
Isaac Lab 2.3.0은 로봇 학습 전반에 걸쳐 대규모 기능 향상을 포함하며, 휴머노이드 조작, 이동 통합, 모방 학습 파이프라인 확장, Dexterous RL 등 다양한 영역에서 새로운 워크플로우를 제공합니다. 이번 버전은 실제 로봇 시스템을 위한 Physical AI 개발을 더욱 쉽고 일관되게 수행하도록 설계되었습니다.
막대
DexSuite는 물체의 회전, 이동, 리프팅과 같은 정교한 손 조작(Dexterous Manipulation)을 학습하기 위한 강화학습 환경으로, 다양한 객체 형태와 물리 조건에서도 견고하게 일반화할 수 있도록 설계된 고난도 RL 스위트입니다.
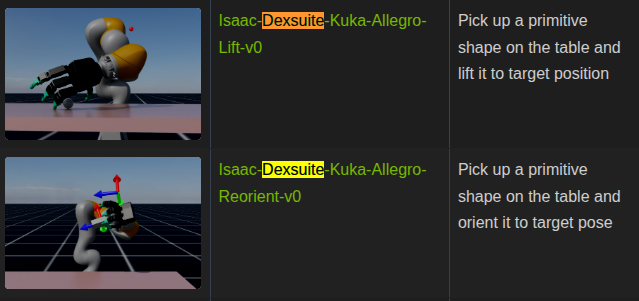
Dexsuite는 손재주 조작을 학습하는 환경
이 환경은 복잡한 손 조작을 시뮬레이션에서 학습하고 실제 로봇으로 전이하는 것을 목표
Dex 환경
DextrAH 및 DexPBT 에 이어, 능숙한 Lift 및 Reorient 환경을 포함한 새로운 DexSuite가 추가되었습니다 . 이 환경은 자동 도메인 무작위화(ADR) 및 PBT(인구 기반 훈련)의 활용도 보여줍니다.


Issac Lab 2.3.0에서는 표면 그리퍼가 관리자 기반 워크플로를 지원하도록 확장되었습니다.
여기에는 SurfaceGripperAction 및 SurfaceGripperActionCfg가 추가되었으며, 표면 그리퍼와 RMPFlow 컨트롤러를 사용한 원격 조작 사례를 보여주는 여러 가지 새로운 환경이 추가되었습니다. 로보티크 그리퍼와 흡착 컵을 탑재한 Franka와 UR10, 그리고 Galbot과 Agibot 로봇을 포함한 새로운 로봇과 변형 모델이 도입되었습니다.
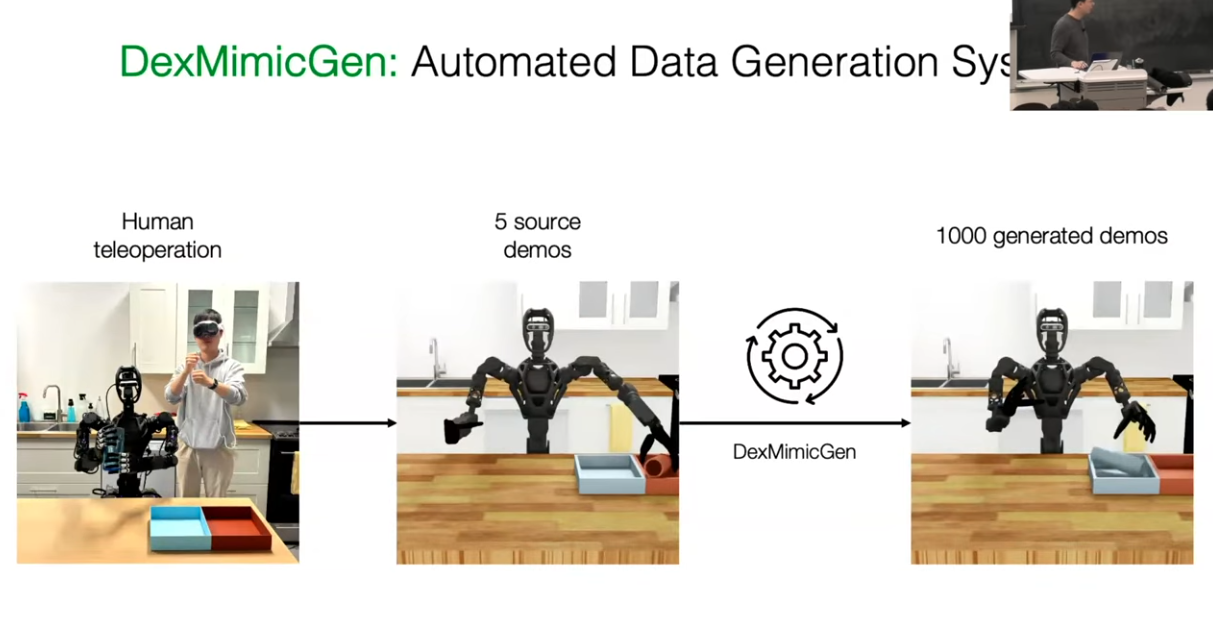
Mimic 모방 학습 파이프라인에 SkillGen 지원이 추가되어 cuRobo와 통합되고, GPU 동작 계획과 기술 분할 데이터 생성 기능이 통합되었습니다. cuRobo는 독점 라이선스 조건을 가지고 있으므로 사용 전에 주의 깊게 검토하시기 바랍니다.
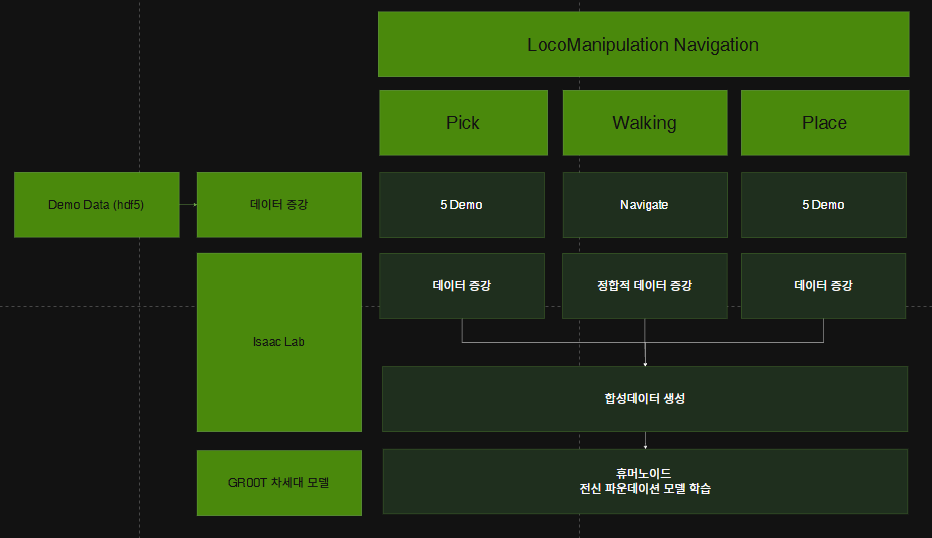
강화학습(RL) 기반 이동과 IK 기반 조작을 결합한 새로운 G1 휴머노이드 환경을 추가했습니다. 테이블탑 픽/플레이스 위치, 목적지 및 지상 장애물의 무작위성을 통해 시연을 보완하기 위해 전체 로봇 내비게이션 스택이 통합되었습니다. 이 방법은 작업을 픽-내비게이션-플레이스 단계로 세분화함으로써, 조작 전용 시연에서 대규모 이동 조작 데이터 세트를 생성할 수 있도록 합니다.
상체 및 하체 컨트롤러를 갖춘 새로운 이동 조작 G1 환경을 추가했습니다. 이를 통해 팔과 손가락을 제어하여 시연하고, 골반의 순간 속도와 높이(vx, vy, wz, h)를 제어하여 이동을 구현할 수 있습니다. 또한, 핑크 기반 역기구학 컨트롤러는 이제 영공간 자세 정규화를 지원하여 허리 자유도를 활성화하고 휴머노이드 로봇의 도달 범위를 확장합니다.

상체 역기구학 제어기가 영공간 자세 작업을 추가하여 휴머노이드 작업에서 허리 움직임을 가능하게 하고, 불필요한 자유도를 선호하는 직립 자세로 정규화함으로써 개선되었습니다. 또한, Vive 및 Manus Glove 지원이 추가되어 원격 조작 장치에 대한 더 많은 옵션을 제공합니다.
탐색 및 데모 증강을 통해 이러한 현장 조작 작업을 확장하여 조작 전용 데모에서 대규모 픽-내비게이션-장소 데이터 세트를 생성할 수 있게 되었습니다.
변화 1: dataset_annotated_g1_locomanip.hdf5 → generated_dataset_g1_locomanip.hdf5
핵심 변화: 정적 조작 데이터 증강
추가되는 데이터:
# 객체 위치를 랜덤하게 배치
new_obj_pose = randomize_object_position()
# 위치: data_generator.py:531
action_noise=subtask_configs[subtask_ind].action_noise
데이터 구조 변화:
# Before (annotated)
{
"demo_0": {
"actions": [28차원], # 손 위치 + 관절
"states": {...}, # 고정된 객체 위치
"subtask_boundaries": [0, 60, 130, 200] # 서브태스크 경계
}
}
# After (generated)
{
"demo_0": {
"actions": [28차원], # 변형된 손 위치
"states": {...}, # 새로운 객체 위치
"subtask_boundaries": [0, 60, 130, 200] # 동일한 경계
},
"demo_1": {...}, # 다른 객체 위치
"demo_2": {...}, # 다른 테이블 위치
...
"demo_999": {...} # 1000개 변형
}
변화 요약:
변화 2: generated_dataset_g1_locomanip.hdf5 → generated_dataset_g1_locomanipulation_sdg.hdf5
핵심 변화: 정적 조작 + 이동 요소 결합
추가되는 데이터:
# 위치: generate_data.py:428
output_data.base_velocity_target = torch.tensor([linear_velocity, 0.0, angular_velocity])
# 위치: generate_data.py:587
output_data.base_path = base_path # A* 경로
# 위치: generate_data.py:585-586
output_data.base_goal_pose = base_goal.get_pose()
output_data.base_goal_approach_pose = base_goal_approach.get_pose()
# 위치: generate_data.py:590-594
output_data.obstacle_fixture_poses = torch.cat(obstacle_poses, dim=0)
# 위치: generate_data.py:319, 367, 426, 480, 541
output_data.data_generation_state = int(LocomanipulationSDGDataGenerationState.NAVIGATE)
output_data.recording_step = recording_step # 원본 데이터 스텝 추적
데이터 구조 변화:
# Before (generated - 정적 조작)
{
"demo_0": {
"actions": [28차원], # 손 위치 + 관절만
"states": {
"base_pose": [고정], # 변하지 않음
"object_pose": [...]
}
}
}
# After (locomanipulation_sdg - 동적 로코마니퓰레이션)
{
"demo_0": {
"actions": [28차원 + 베이스 속도], # 손 + 관절 + 이동
"states": {
"base_pose": [변화함], # 이동 중
"object_pose": [...],
"base_path": [...], # 경로 정보 추가!
"base_goal_pose": [...], # 목표 위치 추가!
"obstacle_fixture_poses": [...] # 장애물 추가!
},
"locomanipulation_sdg_output_data": {
"data_generation_state": 2, # NAVIGATE 상태
"base_velocity_target": [vx, 0, vyaw], # 이동 속도 추가!
"recording_step": 130 # 원본 데이터 추적
}
}
}
변화 요약:
1. dataset_annotated_g1_locomanip.hdf5 → generated_dataset_g1_locomanip.hdf5
의미: 소수의 전문가 데모를 대규모 학습 데이터로 확장
원본 데이터는 5개의 텔레오퍼레이션 데모만 포함합니다. 이는 학습에 부족합니다. 데이터 생성 단계에서는 서브태스크 단위로 분해하고, 객체와 환경의 위치를 바꾸며, 물리적으로 가능한 변형만 선별해 1000개의 데모로 확장합니다.
핵심은 상대적 관계를 유지하는 것입니다. 예를 들어 "손이 객체로부터 10cm 떨어진 위치"라는 관계는 객체 위치가 바뀌어도 유지됩니다. 이를 통해 다양한 위치에서도 동일한 조작 패턴을 학습할 수 있습니다.
결과적으로 로봇은 특정 위치에 의존하지 않고, 객체와의 상대적 관계를 기반으로 조작하는 능력을 학습합니다.
2. generated_dataset_g1_locomanip.hdf5 → generated_dataset_g1_locomanipulation_sdg.hdf5
의미: 정적 조작에 이동 능력을 결합하여 로코마니퓰레이션으로 확장
두 번째 변환은 정적 조작 데이터에 이동 요소를 추가합니다. 원본은 베이스가 고정된 상태에서만 조작합니다. SDG 단계에서는 조작 궤적을 유지하면서 베이스 이동을 추가합니다.
핵심은 조작과 이동의 동시 제어입니다. 로봇은 객체를 잡고 들어올린 후, 들고 있는 상태로 다른 위치로 이동하고, 목표 지점에서 배치합니다. 이 과정에서 경로 계획, 장애물 회피, 이동 중 균형 유지가 포함됩니다.
상태 머신으로 단계를 관리합니다. 그립 → 리프트 → 네비게이션 → 접근 → 배치의 각 단계에서 조작 궤적은 유지하고, 이동 명령만 추가합니다. 이를 통해 이동 중에도 조작을 안정적으로 유지하는 패턴을 학습할 수 있습니다.
결과적으로 로봇은 이동과 조작을 동시에 수행하는 로코마니퓰레이션 능력을 학습합니다.
3. 전체 변환의 철학적 의미
의미: 인간 전문가의 제한된 데모를 로봇이 다양한 상황에서 실행 가능한 지식으로 변환
첫 번째 변환은 공간 일반화입니다. 원본은 특정 위치에서만 작동하지만, 변환 후에는 다양한 위치에서 동일한 조작을 수행할 수 있습니다.
두 번째 변환은 능력 확장입니다. 정적 조작에서 이동 조작으로 확장하여 더 복잡한 작업을 수행할 수 있게 합니다.
이 과정은 인간의 제한된 데모를 로봇이 활용 가능한 지식으로 변환하는 것입니다. 원본은 특정 상황에 종속되어 있지만, 변환을 통해 일반화되고 확장된 지식이 됩니다.
1. 통합 액션 공간의 구조적 의미
액션 벡터의 물리적 구성:
# 위치: g1_locomanipulation_sdg_env.py:180-233
action = [
left_hand_pose[7], # 왼손 위치+방향 (조작)
right_hand_pose[7], # 오른손 위치+방향 (조작)
left_hand_joints[12], # 왼손 관절 (조작)
right_hand_joints[12], # 오른손 관절 (조작)
base_velocity[3] # 베이스 속도 [vx, 0, vyaw] (이동)
] # 총 41차원의 통합 액션 벡터
중요한 점: 신경망은 하나의 출력 벡터에서 조작과 이동을 동시에 예측합니다. 이는 두 작업을 독립적으로 학습하는 것과 다릅니다.
2. 조작 궤적 유지의 학습적 의미
조작 궤적을 유지하면서 이동을 추가하는 이유:
A. 상대적 관계 학습
신경망은 "베이스가 이동해도 손과 객체의 상대적 관계는 유지된다"는 패턴을 학습합니다.
학습 데이터의 패턴:
시점 1: 베이스 위치 (0, 0), 손 위치 (1, 0, 0.5), 객체 위치 (1.2, 0, 0.5)
시점 2: 베이스 위치 (0.5, 0), 손 위치 (1.5, 0, 0.5), 객체 위치 (1.7, 0, 0.5)
신경망이 학습하는 것:
만약 조작 궤적을 바꾸면:
B. 일관성 있는 학습 신호
조작 궤적을 유지하면 신경망은 "조작 패턴은 동일하고, 이동만 추가된다"는 명확한 신호를 받습니다.
학습 과정:
입력: [베이스 위치, 객체 위치, 목표 위치, ...]
출력: [손 위치, 손 관절, 베이스 속도]
신경망이 학습하는 매핑:
- 베이스 위치 변화 → 베이스 속도 변화
- 객체 위치 변화 → 손 위치 변화 (상대적 관계 유지)
- 베이스 속도와 손 위치의 동기화
3. 통합 학습 vs 분리 학습의 차이
분리 학습 (만약 조작과 이동을 따로 학습한다면):
# 조작 정책
manipulation_policy(obs) → [hand_pose, hand_joints]
# 이동 정책
locomotion_policy(obs) → [base_velocity]
문제점:
통합 학습 (현재 방식):
# 통합 정책
locomanipulation_policy(obs) → [hand_pose, hand_joints, base_velocity]
장점:
4. 네트워크 내부의 학습 메커니즘
신경망이 학습하는 숨겨진 패턴:
A. 공간 변환 학습
# 네트워크 내부에서 학습되는 변환:
def forward(obs):
# 공통 특징 추출
features = encoder(obs)
# 조작 특징 (베이스 기준 상대 좌표)
manipulation_features = extract_manipulation(features)
# 이동 특징 (절대 좌표)
locomotion_features = extract_locomotion(features)
# 통합 예측 (상호작용 고려)
hand_pose = manipulation_head(manipulation_features, locomotion_features)
base_velocity = locomotion_head(locomotion_features, manipulation_features)
return [hand_pose, base_velocity]
핵심: 조작 헤드와 이동 헤드가 서로의 정보를 공유하여 상호작용을 학습합니다.
B. 시간적 일관성 학습
조작 궤적을 유지하면 네트워크는 시간에 따른 일관성을 학습합니다.
t=0: 베이스(0,0), 손(1,0,0.5), 베이스속도(0,0,0)
t=1: 베이스(0.1,0), 손(1.1,0,0.5), 베이스속도(0.1,0,0)
t=2: 베이스(0.2,0), 손(1.2,0,0.5), 베이스속도(0.1,0,0)
학습되는 패턴:
5. 데이터 구조가 학습에 미치는 영향
올바른 데이터 구조 (조작 궤적 유지 + 이동 추가):
# 각 시점의 데이터
{
"base_pose": [x, y, yaw], # 변화함
"hand_pose": [x, y, z, qx, qy, qz, qw], # 베이스 기준 상대 위치 유지
"base_velocity": [vx, 0, vyaw], # 이동 명령
"object_pose": [x, y, z, ...] # 변화함
}
신경망이 학습하는 것:
잘못된 데이터 구조 (조작 궤적도 변경):
# 각 시점의 데이터
{
"base_pose": [x, y, yaw], # 변화함
"hand_pose": [완전히 다른 패턴], # 조작 패턴도 변경됨
"base_velocity": [vx, 0, vyaw], # 이동 명령
"object_pose": [x, y, z, ...] # 변화함
}
문제점:
6. 학습된 네트워크의 추론 과정
학습된 네트워크가 실제로 하는 일:
# 추론 시
obs = {
"current_base_pose": [1.0, 0.5, 0.1],
"object_pose": [2.0, 0.5, 0.5],
"goal_pose": [3.0, 1.0, 0.0],
"obstacle_poses": [...]
}
# 네트워크 추론
action = policy(obs)
# action = [hand_pose, hand_joints, base_velocity]
# 네트워크 내부에서 일어나는 일:
# 1. "목표까지 이동해야 함" → base_velocity 계산
# 2. "이동 중에도 객체를 잡고 있어야 함" → hand_pose를 베이스 기준으로 조정
# 3. "베이스가 이동하면 손도 함께 이동해야 함" → 상대적 관계 유지
핵심: 네트워크는 이동과 조작을 동시에 고려하여 일관된 액션을 생성합니다.
7. 왜 이 방식이 중요한가?
A. 물리적 일관성
로봇의 물리적 구조상 베이스가 이동하면 상체도 함께 이동합니다. 조작 궤적을 유지하면 이 물리적 일관성을 학습 데이터에 반영할 수 있습니다.
B. 학습 효율성
명확한 패턴(조작 유지 + 이동 추가)을 제공하면 신경망이 더 빠르고 정확하게 학습합니다.
C. 일반화 능력
베이스 기준 상대 좌표로 조작을 표현하면 다양한 베이스 위치에서도 동일한 조작 패턴을 적용할 수 있습니다.
D. 안정성 보장
이동 중에도 조작 안정성을 유지하는 패턴을 학습하므로, 실제 환경에서도 안정적으로 동작합니다.
요약
"조작 궤적 유지 + 이동 명령 추가"는 신경망이 이동과 조작의 상관관계를 학습하고, 베이스 기준 상대 좌표로 조작을 표현하며, 이동 중에도 조작 안정성을 유지하는 패턴을 학습하도록 돕습니다. 이는 분리 학습보다 통합 학습이 로코마니퓰레이션에 더 적합한 이유입니다.
이 글 공유하기: