기술적 주제, 코딩 튜토리얼 및 최신 기술 인사이트를 심층적으로 알아보세요.

1. 개요 로봇이 실제 환경에서 자율적으로 움직이고 작업을 수행하려면, 매우 많은 수의 학습 데이터가 필요하다. 하지만 현실에서 그 데이터를 직접 수집하는 것은 비용이 많이 들고 시간이 오래 걸린다. 그래서 NVIDIA는 GR00T 생태계라는 이름으로, 로봇이 학습할 데이터를 자동으로 생성하고, 증폭하고, 학습하고, 추론까지 이어지는 전체 파이프라인을 제시하고 있다. 이 문서에서는 특히 그 중에서 GR00T-Dreams와 GR00T-Mimic이 어떻게 다른지, 그리고 어떻게 로봇이 사용할 수 있는 학습 데이터를 만들어내는지 정리한다. 2. GR00T 생태계 전체 구조 GR00T는 단일 모델이 아니라, 로봇 학습 전체 파이프라인을 구성하는 여러 구성요소들의 생태계이다. GR00T 생태계 구성요소 GR00T-Dreams : 새로운 시나리오, 새로운 행동 데이터를 생성하는 역할 – 텔레옵, 이미지·언어 등 적은 입력에서 시작해 행동 비디오 생성 GR00T-Mimic : 이미 존재하는 시연/데모/로봇 데이터를 기반으로 데이터를 다양하게 변형하고 증폭하는 역할(augmentation) Cosmos : Predict / Reason / Transfer – 행동 예측, 3D 이해, 데이터 변환, 증폭 등을 처리하는 모델 모음 Isaac Lab / GR00T-Omni : 로봇의 관절/물리 기반 실제 시뮬레이션 환경 – 여기서 강화학습(policy training)이 진행됨 GR00T-RT / RFM (Robot Foundation Model) : 학습된 정책을 실제 로봇에서 추론·실행하는 단계 즉, Dreams와 Mimic은 데이터 생성 단계, Isaac Lab은 학습 단계, RFM은 실행 단계라고 이해하면 된다. 3. GR00T-Mimic – 기존 데이터를 확장하는 블루프린트 개념 Mimic은 말 그대로 기존에 가지고 있는 시연 데이터(demonstration)를 모방하고, 변형하고, 확대하는 파이프라인이다. 입력은 다음과 같다: 사람 텔레옵 데이터 기존 로봇 조작 trajectory Isaac Sim에서 기록된 데이터 사람/로봇 전문가 데모 이러한 데이터에서 환경을 바꾸거나, 조명·배치·속도·물체 상태 등을 다양하게 바꿔서 새로운 학습 데이터를 대량 생성한다. 특징 입력: 이미 존재하는 trajectory 출력: 동일 작업(task)에 대한 수천~수만 개의 변형 trajectory 목적: 특정 작업에서 로봇의 숙련도 향상 기술요소: Isaac Sim, Isaac Lab, Cosmos-Transfer 등을 이용한 증폭 요약 Mimic은 “기존 작업을 잘하게 만드는” 데 최적화된 방식이다. 4. GR00T-Dreams – 새로운 시나리오를 만드는 방식 개념 Dreams는 처음부터 새로운 작업 시나리오를 만든다. 아주 적은 입력만으로도 시작할 수 있다. 예시: 한 장의 이미지 텍스트 설명 짧은 텔레옵 시연 Dreams는 이렇게 최소 입력을 기반으로 행동 비디오를 생성하고, Cosmos가 그 비디오를 분석하여 로봇이 실제로 학습할 수 있는 trajectory로 변환한다. 핵심 특징 입력: 최소 정보(이미지/텍스트/간단한 시연) 출력: 완전히 새로운 작업 trajectory 목적: 로봇의 범용성(Generalization) 강화 기술요소: DreamGen, Cosmos Predict/Reason, pose reconstruction 5. Dreams는 단순한 비디오 생성 기술이 아니다 많은 사람들이 “Dreams는 그냥 비디오 생성 기술 아닌가?”라고 생각한다. 하지만 진짜 중요한 것은 비디오 이후 단계이다. Dreams는 비디오를 생성한 뒤, 로봇 학습에 필요한 구조화된 데이터로 변환하는 전체 파이프라인을 포함한다. 즉, Dreams는 비디오 → 3D Pose → 로봇 trajectory → 물리 기반 토크로 이어지는 전체 변환을 수행한다. 6. GR00T-Dreams 파이프라인: 비디오 → 로봇 학습 데이터 여기서 Dreams의 기술력이 가장 잘 드러난다. ① DreamGen: 행동 비디오 생성 입력: 텍스트, 이미지, 짧은 시연 출력: 자연스러운 사람 행동 영상 아직 joint 데이터는 없음 ② Cosmos Predict/Reason: 3D Pose Reconstruction 비디오의 각 프레임에서 다음이 추출된다. 3D skeleton 손 orientation 신체 segment trajectory 물체-손 상호작용 픽셀 기반 영상이 3D 구조화 동작으로 바뀌는 단계다. ③ Retargeting: 인간 동작 → 로봇 관절공간 이 3D 인간 행동을 로봇 관절공간(q, qdot)으로 변환한다. joint limit balance constraints reachable workspace 로봇의 kinematics이 모두 반영된다. 이 단계에서 Action Tokens(로봇 행동 표현) 가 생성된다. ④ Inverse Dynamics: 물리량 재구성 로봇이 실제로 실행하려면 필요한 다음 물리값을 계산한다. torque contact force momentum foot placement force 결과적으로 Dreams는 로봇이 즉시 정책 학습에 사용할 수 있는 완전한 trajectory 데이터를 생성한다. 7. Mimic vs Dreams 요약 비교 8. 마무리 Dreams와 Mimic은 서로 목적과 기술이 다르지만, 둘 다 로봇 학습 데이터 확보에서 핵심적인 역할을 한다. Mimic: 이미 알고 있는 작업을 더 잘하게 만드는 방식 Dreams: 새로운 작업을 새로 생성해 로봇의 범용성을 키우는 방식 Cosmos: Dreams/Mimic의 데이터 처리, 변환을 수행하는 기반 모델 Isaac Lab: 로봇의 정책을 학습하는 환경 RFM: 실제 로봇에서 학습된 정책을 실행하는 모델 9. 관련 및 참고 링크 Training Humanoid Robots With Isaac GR00T-Dreams https://www.youtube.com/watch?v=pMWL1MEI-gE Teaching Robots New Tasks With GR00T-Dreams https://www.youtube.com/watch?v=QHKH4iYYwJs GR00T: NVIDIA Humanoid Robotics Foundation Model https://www.youtube.com/watch?v=ZSxYgW-zHiU Isaac GR00T-Mimic: Isaac Lab Office Hour https://www.youtube.com/watch?v=r24CiGLYFQo
2025년 12월 4일

1. Omniverse가 요구하는 GPU 구조 Omniverse는 NVIDIA RTX 기술을 기반으로 동작한다. 따라서 GPU에 RT Core와 Tensor Core가 모두 있어야 실시간 렌더링, 센서 시뮬레이션, Path Tracing 등의 기능이 정상적으로 작동한다. Omniverse 주요 기능 중 RT Core 없이 수행이 불가능하거나 성능이 심각히 저하되는 기능은 다음과 같다. RTX 실시간 렌더링 Path Tracing RTX Lidar, RTX Camera USD 기반 대규모 씬 가속 GPU PhysX 기반 물리 시뮬레이션 Sensor RTX 기반 로봇 환경 시뮬레이션 전반 결론적으로, Omniverse는 RT Core 없는 GPU에서는 성능과 기능 모두 제대로 작동하지 않는다. 2. AI 전용 GPU가 Omniverse에 적합하지 않은 이유 AI 전용 GPU(B300, B200, H100, H200, A100, V100)는 RT Core가 없다. 이로 인해 다음과 같은 문제가 발생한다. Omniverse 렌더링 성능이 극도로 낮아짐 RTX 기반 센서 시뮬레이션 불가 Path Tracing 불가 실시간 시각화 렌더링이 사실상 불가능 Isaac Sim의 그래픽 기반 시각화 불가 대규모 USD 씬 로딩 시 GPU 가속을 거의 활용하지 못함 실행 자체는 되지만, 실무에서는 사용할 수 없는 수준이다. AI 학습에는 매우 뛰어나지만 디지털트윈, 시뮬레이션 분야에는 적합하지 않다. 3. RTX 기반 GPU가 Omniverse에 최적화된 이유 RTX 계열 GPU(L40S, RTX PRO 6000, RTX 6000 Ada 등)는 RT Core와 Tensor Core를 포함하고 있으며, 다음 기능이 하드웨어 수준에서 가속된다. 실시간 RTX 레이트레이싱 RTX 센서 시뮬레이션 대규모 USD 씬 렌더링 딥러닝 기반 노이즈 처리 GPU PhysX 기반 물리 시뮬레이션 AMR, 휴머노이드 로봇, 로봇팔 등 환경에서의 실시간 반응형 시뮬레이션 결론적으로 Omniverse, Isaac Sim, 디지털트윈, 산업용 시각화, 센서 시뮬레이션 업무는 RTX 계열 GPU를 반드시 요구한다. 4. GPU 제품군 구분 (RT Core 기반 여부) 5. RTX PRO 6000 (Blackwell Server Edition) RTX PRO 6000은 NVIDIA의 최신 Blackwell 기반 전문가용 GPU로, AI, 시뮬레이션, 그래픽, 디지털트윈 워크로드를 모두 처리할 수 있는 범용 고성능 GPU이다. 특히 Omniverse 및 Isaac 시뮬레이션에 필요한 4세대 RT Core + 5세대 Tensor Core를 모두 갖추고 있어 RTX 기반 시뮬레이션에 최적화되어 있다. 주요 특징 Blackwell 아키텍처 기반 24,064 CUDA Cores 5세대 Tensor Cores (AI·시뮬레이션 가속) 4세대 RT Cores (실시간 레이트레이싱·RTX 센서 시뮬레이션) 96GB ECC GDDR7 메모리 PCIe Gen5 x16 멀티 GPU 구성 및 데이터센터 서버 환경 지원 AI + 그래픽 + 시뮬레이션을 모두 처리하는 범용 전문가 GPU 왜 Omniverse/Isaac에 적합한가 RT Core 기반의 실시간 RTX 렌더링 및 RTX Lidar/Camera 지원 대규모 USD 씬 렌더링 가속 대용량 VRAM(GDDR7 96GB)으로 복잡한 디지털트윈 환경 처리 로봇 시뮬레이션, AMR 센서 재현, 물리 기반 환경 구성이 빠르게 가능 그래픽/AI/시뮬레이션이 혼합된 복합 워크로드에 최적화 6. 로봇 학습(Isaac Sim & Isaac Lab) 기준 GPU 선택 로봇 관련 NVIDIA 툴의 GPU 요구사항은 “렌더링/센서 포함 여부”에 따라 크게 달라진다. 1) Isaac Sim (시각화 + RTX 센서 + 물리 포함) 필수 조건 GPU 가속 PhysX RTX 기반 센서 시뮬레이션 (RTX Lidar, RTX Camera 등) 실시간 렌더링(RTX 기반 비주얼 컴퓨팅) 필수 GPU RTX PRO 6000 L40S RTX 6000 Ada A6000/A40 AI 전용 GPU(B200/B300/H100/H200/A100/V100)는 시각화, 센서 시뮬레이션, RTX 기반 렌더링이 불가능하거나 극도로 비효율적이므로 Isaac Sim “시뮬레이션 실행”에는 적합하지 않다. 2) 합성데이터(Synthetic Data) 생성 합성데이터 생성은 카메라 및 LiDAR 등 센서 기반 AI 모델을 학습시키기 위해 현실을 시뮬레이션으로 대체하여 대량의 레이블된 데이터를 자동 생성하는 과정이다. NVIDIA Isaac Sim은 이 합성데이터 파이프라인 전용 기능을 포함한다. 특징적으로, 합성데이터는 수동 라벨링 없이도 다음 데이터를 자동 생성할 수 있다. RGB 이미지 Semantic Segmentation Instance Segmentation Bounding Boxes Depth Point Cloud LiDAR returns 2D/3D Keypoints Occlusion 정보 Material/Lighting 변화가 반영된 Multi-view 데이터 합성데이터 생성이 필요한 이유 현실에서 데이터 수집이 어려움(비용·환경 위험·시간 문제) 라벨링 자동화 현실에서는 드물게 발생하는 edge case를 의도적으로 대량 생성 가능 다양한 조명, 재질, 위치 등을 통제된 방식으로 무한 생성 가능 카메라/LiDAR 센서 파이프라인을 실제와 동일하게 모델링 가능 즉, 합성데이터는 로봇 Perception 학습에서 데이터 다양성, 규모, 난이도를 자유롭게 조절할 수 있는 핵심 기술이다. https://developer.nvidia.com/blog/build-synthetic-data-pipelines-to-train-smarter-robots-with-nvidia-isaac-sim 3) Isaac Lab (Headless 학습 — 렌더링 없음) Isaac Lab은 강화학습 및 로봇학습을 위해 Headless(비시각화) 실행이 가능하다. RTX 필요 없음 RT Core 없어도 됨 센서 시뮬레이션을 끄고, GPU PhysX만 사용하면 됨 따라서 아래 AI 전용 GPU도 Isaac Lab 학습에는 사용 가능하다. B300 B200 H200 H100 A100 V100 Headless에서는 오직 PhysX 병렬 시뮬레이션 정책 학습 모델 업데이트가 중요하기 때문에 AI 가속기 GPU가 더 효율적일 수도 있다. 플랫폼 고려사항: Isaac Lab의 JAX 기반 SKRL 학습은 aarch64 아키텍처(예: DGX Spark)에서 기본적으로 CPU-only로 실행되지만, JAX를 소스에서 빌드하면 GPU 지원이 가능합니다(현재 Isaac Lab에서 검증되지 않음). 7. AI 학습 + Omniverse를 동시에 운영하는 구성 전략 Omniverse 기반의 디지털트윈/센서 시뮬레이션과 대규모 AI 학습은 사용하는 GPU 아키텍처가 서로 다르기 때문에 한 대의 GPU만으로 모든 워크로드를 해결하기는 어렵다. 단, 목적, 규모, 예산에 따라 다음 3가지 구성이 일반적으로 사용된다. 1) 소규모 테스트 및 개발 단계 “단일 RTX GPU 워크스테이션 구성” RTX 기반 GPU(예: RTX PRO 6000, RTX 6000 Ada)는 다음을 하나의 워크스테이션에서 동시에 수행할 수 있다. Omniverse / Isaac Sim 실행 RTX Lidar, RTX Camera 등 센서 시뮬레이션 로봇 행동 시각화 경량 AI 학습 또는 추론 (중, 소형 모델 수준) 특징 테스트, PoC, 초기 개발에 적합 디지털트윈과 AI 모델을 같은 장비에서 확인하기 쉬움 하드웨어 구성 비용이 상대적으로 낮음 렌더링/시각화 기반 워크로드가 중심인 경우 충분함 한계 LLM, 대규모 강화학습, 수천 환경 병렬 학습 등의 고부하 AI 학습은 비효율적 VRAM 용량이 충분해도 AI 전용 GPU 대비 학습 속도가 크게 떨어짐 이 구성에 적합한 GPU RTX PRO 6000 RTX 6000 Ada L40S A6000 결론 “Omniverse + 중간 규모 AI 작업까지 가능한 범용 개발 워크스테이션” 2) 중~대규모 로봇/RL(AI) 학습 + 시뮬레이션 운영 “RTX GPU + AI GPU 혼합 서버 구성” 이 구조는 실제 연구소, 기업에서 가장 많이 사용된다. 용도 분리 RTX GPU → Omniverse / Isaac Sim / 센서 시뮬레이션 AI GPU → Isaac Lab 강화학습 / LLM / 딥러닝 학습 장점 Omniverse의 RTX 시각화와 Isaac Lab의 headless 병렬 학습을 서로 다른 GPU에서 최적 성능으로 실행 AI GPU(B100/B200/H100/H200/A100)가 학습 병렬화 속도 극대화 RTX GPU는 그래픽/센서/물리 시뮬레이션을 전담하므로 지연이 감소 구성 예시 GPU0: RTX PRO 6000 → Omniverse/시뮬레이션 GPU1~8: H100 또는 B200 → 강화학습/AI 기반 제어/모델 학습 결론 “AI 학습 속도 + Omniverse 그래픽 성능을 모두 보장하는 가장 이상적인 아키텍처” 3) 대규모 프로젝트 운영 단계 “서버 이원화(전용 서버 분리)” 완전히 분리하여 운영하는 방식. Omniverse 전용 서버 (RTX GPU) RTX 기반 센서 대규모 USD 렌더링 AMR, 휴머노이드 로봇 등 시각화 실시간 Twin Viewer AI 학습 전용 서버 (AI GPU) Isaac Lab headless 병렬 학습 정책 학습, PPO/SAC 등 LLM, 대규모 perception 모델 학습 장점 작업 간섭 없음 (GPU contention 0%) 확장성 최고 기업 프로젝트/프로덕션 환경에서 안정적 디지털트윈은 Low Latency 유지 AI 학습은 최대 병렬성 유지 이 구성은 NVIDIA가 실제 기업·로봇고객에게 권장하는 공식 구조와 동일하다. 결론 “대규모 디지털트윈 + 로봇 AI 학습을 운영하는 엔터프라이즈 표준 구성” 8. NVIDIA Brev: GPU 구매 전 테스트 및 시뮬레이션 검증을 위한 최적의 선택 NVIDIA Brev(Brev.dev)는 다양한 GPU 서버를 시간 단위로 대여하여 즉시 사용할 수 있는 클라우드 GPU 플랫폼이다. GPU를 실제로 구매하기 전에, Omniverse/Isaac Sim/Isaac Lab이 어느 GPU에서 가장 잘 돌아가는지 실환경에 가깝게 테스트해야 할 때 매우 유용하다. Brev는 특히 다음과 같은 케이스에 강점이 있다. RTX 기반 Omniverse가 실제로 잘 구동되는지 미리 검증 RTX PRO 6000, RTX 6000 Ada 등 고급 GPU를 구매 전 테스트 Isaac Sim/Isaac Lab의 설정을 클라우드에서 바로 실험 AI 전용 GPU(H100/A100)를 활용한 강화학습 속도 체험 GPU 스케일링/서버 구성 실험 큰 지출 없이 빠르게 GPU 벤치마크 확인 Brev에서 제공되는 대표 GPU (2025 기준) Brev는 공급자별로 제공되는 GPU가 달라지지만, 일반적으로 다음 GPU를 사용할 수 있다. RTX 기반 (Omniverse 사용 가능) RTX PRO 6000 RTX 6000 Ada RTX A6000 L40S L40 AI 학습 전용 (Headless Isaac Lab 및 LLM 학습 가능) A100 H100 H200(일부 리전) B200/B300(순차 확대 중) 즉, Brev는 “RTX 계열 + AI 계열”을 모두 제공하기 때문에 실제 로컬에서 구축하려는 서버 아키텍처를 클라우드에서 먼저 완전히 동일하게 실험할 수 있다.
2025년 12월 4일

WFM (World Foundation Model) 한눈에 보기 정의 World Foundation Model(WFM)은 텍스트, 이미지, 영상 등 다양한 입력으로부터 현실 세계의 상태와 변화를 시퀀스 단위로 모사, 예측, 생성하는 대규모 모델이다. WFM은 물리적 시뮬레이션(예:NVIDIA Cosmos)을 통해 로봇, 자율주행 등 Physical-AI 분야에서 합성 데이터 생성 및 환경 예측에 활용된다. 이 계열은 실제 센서, 로봇 동작, 자율주행 환경을 포함한 “World-as-Physics” 방향의 모델이다. 한편, DeepMind Genie 3, OpenAI Sora2 등은 세계의 물리 규칙뿐 아니라 시각적 인과성, 인지적 패턴, 언어적 맥락까지 학습하는 “World-as-Perception / Understanding” 계열의 WFM이다. 이들은 텍스트나 영상 입력만으로 환경의 변화를 시뮬레이션하거나 에이전트가 인지적으로 상황을 해석 하도록 학습한다. Meta V-JEPA 2는 영상의 일부 정보를 가리고 남은 프레임으로 미래 장면을 예측하는 비지도 자기학습 (Video self-supervised)모델이다. 화면의 공간, 시간적 패턴을 추론해 장면 이해와 행동 계획을 동시에 향상시키며, 이는 WFM 중에서도 “World-as-Prediction / Understanding” 방향을 대표한다. 넓은 의미의 WFM (정확한 개념 정리) 왜 필요한가 현실 세계 데이터를 직접 수집하는 데 비용과 위험이 크므로, 다양한 환경과 상황을 가상 공간에서 빠르게 생성하고 테스트할 수 있어야 하며, 이를 통해 로봇, 자율주행 모델을 시뮬레이션 단계에서 충분히 학습하고, 실제 환경으로 옮기는(Sim-to-Real) 과정의 리스크와 비용을 줄일 수 있다. 핵심 능력 장면 / 세계 이해·예측 (비디오 수준) — 과거 프레임 기반 예측, 영상 인과성 학습 등 (예: V-JEPA 계열) 세계 / 환경 생성 (텍스트 → 인터랙티브 월드 / 비디오) — 텍스트 프롬프트로 환경 생성 (예: Genie 3) 합성 데이터 생성 및 파이프라인 공급 — 로봇 / 자율주행 / 비전 시스템 학습용 데이터 대량 제공 대표 모델 / 플랫폼 (2025 기준) 한눈에 비교 차트 (2025 성능 기준, 공식 벤치마크) 경계 및 역할 구분 WFM은 단순한 비디오 생성기를 넘어선 개념이다. “생성 + 이해 + 예측 + 합성 데이터 제공”이 모두 포함된 통합적 모델이다. 이 정의는 NVIDIA Cosmos 설명 문서에서도 반영되고 있다. 관련 자료:NVIDIA Announces Major Release of Cosmos World Foundation Models— NVIDIA Newsroom WFM과 RFM(Robot Foundation Model)은 역할이 명확히 구분된다. WFM: 환경/세계의 디지털 트윈을 구축하여 시뮬레이션 가능한 공간을 만든다. RFM: 그 환경 위에서의 로봇이 정책, 행동을 학습하고 제어 모델을 만든다. 이 역할 구분은 Cosmos 논문에서도 “world model + policy model” 구조로 명시되어 있다. 위에 그림은 Cosmos 논문에 제시된 WFM의 기본 구조로, 과거의 관측값 x₀:ₜ 과 로봇의 행동 입력 cₜ 을 받아, 다음 세계 상태 x̂ₜ₊₁ 을 예측하는 과정을 보여준다. 이는 곧 WFM이 환경을 예측하고, RFM이 행동을 결정하는 구조적 관계를 시각적으로 설명한다. (관련 논문: Cosmos World Foundation Model Platform for Physical AI — arXiv 관련 링크: arXiv) 이 구분은 WFM의 생성, 예측 중심 역할과 로봇 제어 중심 RFM의 역할 분리를 강조하는 구조적 관점에서 유용하다. Omniverse / NVIDIA 환경과의 연결 WFM, 특히 NVIDIA Cosmos,는 Omniverse 라이브러리와 함께 제공되어 다음 기능을 통합 지원한다. 현실 세계를 캡처 및 재구성 → 디지털 트윈 생성 합성 데이터 대량 생성 로봇 시뮬레이션, AI 에이전트 학습 환경 구축 (관련 기사: NVIDIA Opens Portals to World of Robotics With New Omniverse Libraries and Cosmos Physical AI Models — NVIDIA Newsroom) 또한, Omniverse Blueprints가 Cosmos WFM과 연결되어 로봇 준비 시설(robot-ready facilities)과 대규모 합성 데이터 생성을 가능하게 한다는 발표도 확인된다. (관련 기사: NVIDIA Omniverse Physical AI Operating System Expands to More Industries and Partners) 글로벌 WFM 연구 동향 (Beyond NVIDIA Cosmos) WFM(World Foundation Model)은 단일 기업의 기술이라기보다, AI가 “세계를 이해, 예측, 생성”하는 공통 목표를 향한 범세계적 연구 트렌드다. 아래는 물리 중심의 WFM을 넘어, 인지, 시각, 언어 기반 세계 모델링으로 확장된 대표 흐름이다. 1. World-as-Generation (세계 생성 중심) 2. World-as-Perception / Understanding (세계 이해 중심) 3. World-as-Physics (세계 시뮬레이션 중심) WFM이 학습하는 세계의 다층 데이터 구조 WFM이 다루는 데이터 스펙트럼은 단순한 시각, 물리 정보에 그치지 않는다. 실제로 WFM은 World / Automation / Robot / Asset / Analysis Data의 다층 구조를 통합적으로 학습하며, 이를 통해 세계의 상태와 변화를 예측하는 ‘통합 세계 모델(Integrated World Model)’로 발전한다. 이 다섯 가지 데이터는 WFM의 입력 도메인을 구성하며, Cosmos, Genie, V-JEPA 등 각 모델은 특정 도메인(물리, 시각, 인지)에 집중하여 “세계를 이해하고 생성”하는 공통 목표를 지닌다. 다섯 가지 데이터 구조의 역할은 다음과 같다. 이 다층 데이터 구조는 WFM이 세계를 이해하고 시뮬레이션하는 입력 기반으로 작동하며, 결과적으로 AI가 “맥락적 세계 인식(Contextual World Modeling)”을 수행할 수 있도록 돕는다.
2025년 11월 4일
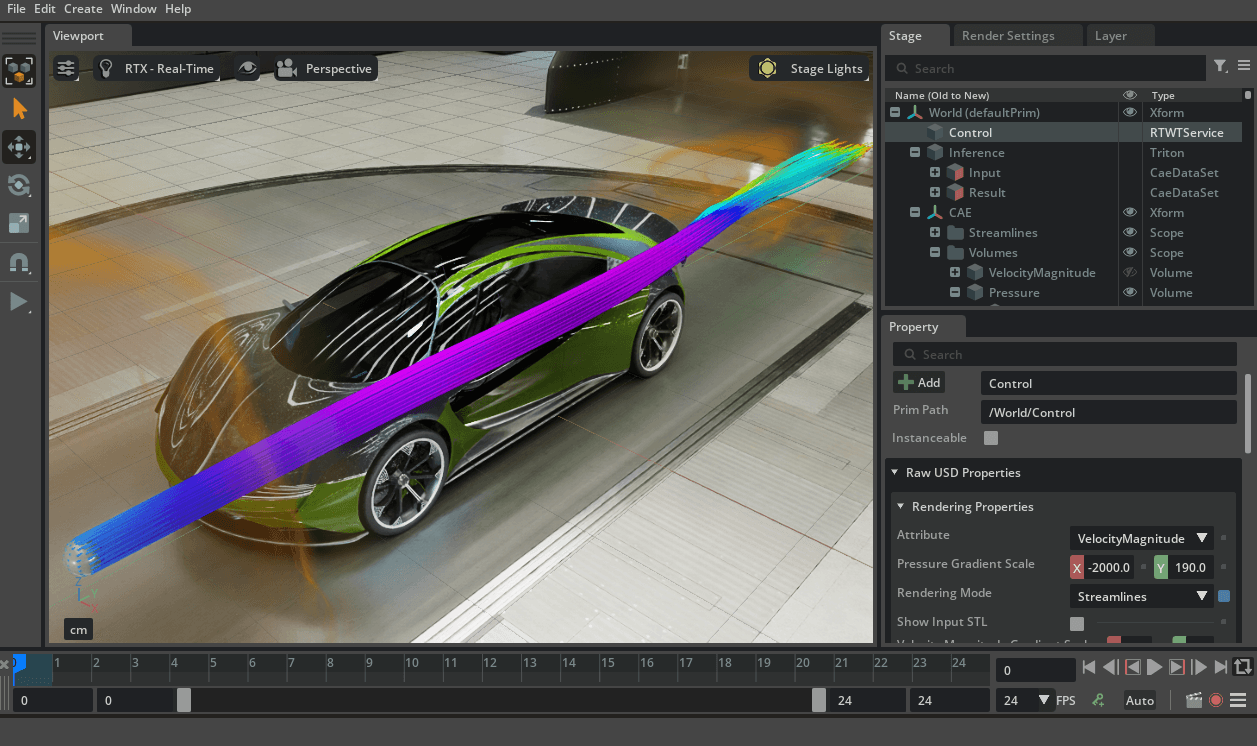
Kit-CAE: CAE 결과를 Omniverse로 연결하는 브릿지 개요 CAE 해석 결과는 보통 전용 뷰어(예: ParaView, Ansys 후처리 툴)에서만 확인할 수 있었습니다. 하지만, NVIDIA는 이러한 결과를 Omniverse로 가져와 실시간 시각화, 협업, AI 연동까지 가능하게 하기 위해 Kit-CAE를 제공합니다. https://developer.nvidia.com/blog/how-to-run-ai-powered-cae-simulations/ https://github.com/NVIDIA-Omniverse/kit-cae/tree/main 필요성 해석 데이터는 복잡하고 무겁지만, 시각화는 보통 단일 사용자/로컬 분석에 한정 실제 산업 현장에서는 설계–해석–시뮬레이션–운영이 긴밀히 연결되어야 함 기존 도구만으로는 실시간 협업, AI/디지털 트윈 연동이 어렵다는 한계 목적 CAE 결과 데이터(.cgns / .vtk(.vti) / .npz)를 Omniverse에서 직접 임포트·시각화 결과를 USD로 표준화해 Isaac Sim/Composer 등과 같은 씬에서 재사용·협업 AI 파이프라인 연결: Physics NeMo(학습) → NIM(API 추론) → 장면에 즉시 반영 실시간 디지털 트윈: 로봇·설비 상태 변화에 따른 즉시 예측, 표시 대용량 데이터 최적화: IndeX/NanoVDB 기반으로 고품질·실시간 렌더링 1) 무엇을 위한 도구인가? CAE 해석 결과(.cgns / .vtk / .npz)를 Omniverse에서 직접 불러와 시각화 External Faces, Streamlines, Volume/Slice 등 기본 후처리 가능 USD 기반으로 Isaac Sim, USD Composer와 매끄럽게 연동 Kit-CAE의 Streamlines / Flow 동적 시각화 기존 CAE 결과 데이터(속도장, 압력장 등)를 불러와서 → 이를 실시간으로 시각적으로 표현하는 기능 여기서 “실시간”은 다시 물리 해석을 계산하는 게 아니라, 이미 주어진 벡터 필드(예: 유동 속도) 위에 Streamline을 생성하거나 입자 애니메이션을 그려주는 것 따라서 CAE solver 역할은 없고, 후처리 + 인터랙티브 시각화 도구에 가까움 GPU 가속 처리 이런 Streamlines, Voxelization, Flow 시각화는 연산량이 많기 때문에 GPU 가속 라이브러리가 필수 Kit-CAE는 Omniverse Kit 확장으로 구현되어 있으며, NVIDIA가 만든 Warp 라이브러리를 옵션으로 통합해서 사용 가능함 예: Warp 기반 Streamlines (빠르지만 일부 요소 타입만 지원) 예: GaussianWarp Voxelization (GPU 병렬 복셀화, Gaussian kernel 기반) Warp의 역할 Warp는 NVIDIA가 Omniverse용으로 만든 CUDA 기반 GPU 물리 연산 프레임워크 Streamline 적분, 점 클라우드 → 볼륨 복셀화 같은 수치 연산을 CPU가 아니라 GPU에서 병렬로 처리 Kit-CAE에서 Streamlines, Flow, Voxelization 같은 알고리즘에 Warp 버전이 제공되는 이유 2) ParaView와의 차이 USD 통합 협업: 여러 팀이 동시에 동일 장면 접근 디지털 트윈 연계: 해석 결과를 로봇/설비 시뮬레이션 위에 오버레이 AI 파이프라인 연결: Physics NeMo → NIM API → Kit-CAE 시각화 Python 자동화: 반복 작업/스크립트 기반 워크플로우 지원 ParaView = 해석 후처리 뷰어 Kit-CAE = Omniverse 생태계와 이어주는 확장 플랫폼 3) 사용 패턴 CAE 데이터: 기존 해석 툴(Ansys, Star-CCM+, OpenFOAM 등)에서 얻은 시뮬레이션 결과 Curator: 이 데이터를 AI 학습에 적합한 포맷으로 변환 PhysicsNeMo: 변환된 데이터를 기반으로 AI surrogate 모델 학습 NIM: 학습된 모델을 API 형태로 배포해 외부에서 쉽게 호출 가능 Omniverse: Kit-CAE를 통해 API 결과를 불러와 실시간 3D 시각화 및 디지털 트윈 환경에서 활용 A. 비교 및 분석 모드 (연구/해석자용) 기존 CAE 툴(Ansys, Star-CCM+, OpenFOAM 등)에서 해석 결과 파일(.cgns, .vtk, .npz)을 출력 Kit-CAE에서 데이터를 Import하여 시각화 NIM으로 배포된 AI surrogate 모델의 추론 결과를 API 호출로 받아옴 동일한 Omniverse 씬에서 기존 해석 결과와 AI 예측 결과를 나란히 비교 가능 활용 맥락 연구, 개발자가 실제 해석 데이터와 AI 예측 결과의 정확성을 직관적으로 비교 빠른 설계안 검토, 반복 실험 없이 AI 모델 신뢰성 평가 B. 실시간 디지털 트윈 모드 (운영/시뮬레이션용) 기존 해석 데이터로 Physics NeMo surrogate 모델 학습 후 NIM API로 배포 AI 모델이 즉시 물리 해석 결과(유동장, 응력, 온도 분포 등)를 반환 Isaac Sim 같은 Omniverse 앱에서 로봇·설비가 동작할 때 실시간 상태 데이터(속도, 위치, 온도 등)를 NIM API로 전송 Kit-CAE가 해당 결과를 USD 씬 위에 시각화하여 실시간 피드백 제공 활용 맥락 제조 공정 디지털 트윈: 설비 동작 중 발생할 열응력, 변형을 실시간으로 확인 물류센터 시뮬레이션: AMR 로봇 이동 시 발생하는 공기 흐름/온도 변화를 즉시 예측 및 표시 로봇, AI 학습 환경: 시뮬레이션 속에서 물리적 feedback loop을 포함해 강화학습 진행 Flow NanoVDB concept_car.npz Kit-CAE의 예제(예: Streamlines, Volume 렌더링 등)는 기존 CAE 해석 데이터를 실시간으로 시각화하는 기능으로, 이는 “동적으로 유체가 움직이는 것처럼 보이는 애니메이션”을 말합니다. 동적인 시각화지만 AI는 포함되지 않습니다. Streamlines 및 Flow 시각화는 기본적으로 기존 해석 데이터(예: 속도 벡터 필드)를 기반으로 실시간으로 경로를 갱신해 보여주는 기능입니다. 예를 들어, Seed Sphere를 움직이면, 그 위치에 맞춰 Streamlines가 즉시 업데이트되어 유체 흐름이 움직이는 것처럼 보이죠. 하지만 이는 시뮬레이션 실행(AI 또는 물리 해석 계산)이 아니라, 단순히 시각적 업데이트에 불과합니다. AI 기반 동적 예측과의 차이점
2025년 11월 4일
