
Omniverse는 NVIDIA RTX 기술을 기반으로 동작한다.
따라서 GPU에 RT Core와 Tensor Core가 모두 있어야 실시간 렌더링, 센서 시뮬레이션, Path Tracing 등의 기능이 정상적으로 작동한다.
Omniverse 주요 기능 중 RT Core 없이 수행이 불가능하거나 성능이 심각히 저하되는 기능은 다음과 같다.
결론적으로, Omniverse는 RT Core 없는 GPU에서는 성능과 기능 모두 제대로 작동하지 않는다.

AI 전용 GPU(B300, B200, H100, H200, A100, V100)는 RT Core가 없다.
이로 인해 다음과 같은 문제가 발생한다.
실행 자체는 되지만, 실무에서는 사용할 수 없는 수준이다.
AI 학습에는 매우 뛰어나지만 디지털트윈, 시뮬레이션 분야에는 적합하지 않다.

RTX 계열 GPU(L40S, RTX PRO 6000, RTX 6000 Ada 등)는 RT Core와 Tensor Core를 포함하고 있으며,
다음 기능이 하드웨어 수준에서 가속된다.
결론적으로 Omniverse, Isaac Sim, 디지털트윈, 산업용 시각화, 센서 시뮬레이션 업무는 RTX 계열 GPU를 반드시 요구한다.
| 구분 | GPU 모델 | RT Core | Omniverse 가능 여부 | Isaac Sim (시각화/센서) | Isaac Lab (Headless 학습) | 주요 특징 |
|---|---|---|---|---|---|---|
| AI 학습 전용 GPU | B300 | 없음 | 불가 | 불가 | 가능 | Blackwell AI 전용, 초고속 LLM,RL,DL 학습, 270GB HBM3e (B300 Ultra 기준) |
| B200 | 없음 | 불가 | 불가 | 가능 | 고성능 AI 학습용, 192GB HBM3e | |
| H200 | 없음 | 불가 | 불가 | 가능 | H100 대비 VRAM 증가(141GB HBM3e), AI 학습 최적 | |
| H100 | 없음 | 불가 | 불가 | 가능 | 대규모 AI 학습용, 80GB HBM3 | |
| A100 | 없음 | 불가 | 불가 | 가능 | AI 학습용 대표 모델, 80GB HBM2e | |
| V100 | 없음 | 불가 | 불가 | 가능 | 구세대 AI 가속기, 32GB HBM2 | |
| RTX 기반 GPU | RTX PRO 6000 (Blackwell) | 있음 (4세대) | 가능 |

RTX PRO 6000은 NVIDIA의 최신 Blackwell 기반 전문가용 GPU로,
AI, 시뮬레이션, 그래픽, 디지털트윈 워크로드를 모두 처리할 수 있는 범용 고성능 GPU이다.
특히 Omniverse 및 Isaac 시뮬레이션에 필요한 4세대 RT Core + 5세대 Tensor Core를 모두 갖추고 있어 RTX 기반 시뮬레이션에 최적화되어 있다.
주요 특징
왜 Omniverse/Isaac에 적합한가
로봇 관련 NVIDIA 툴의 GPU 요구사항은 “렌더링/센서 포함 여부”에 따라 크게 달라진다.
1) Isaac Sim (시각화 + RTX 센서 + 물리 포함)

필수 조건
필수 GPU
AI 전용 GPU(B200/B300/H100/H200/A100/V100)는
시각화, 센서 시뮬레이션, RTX 기반 렌더링이 불가능하거나 극도로 비효율적이므로 Isaac Sim “시뮬레이션 실행”에는 적합하지 않다.
2) 합성데이터(Synthetic Data) 생성
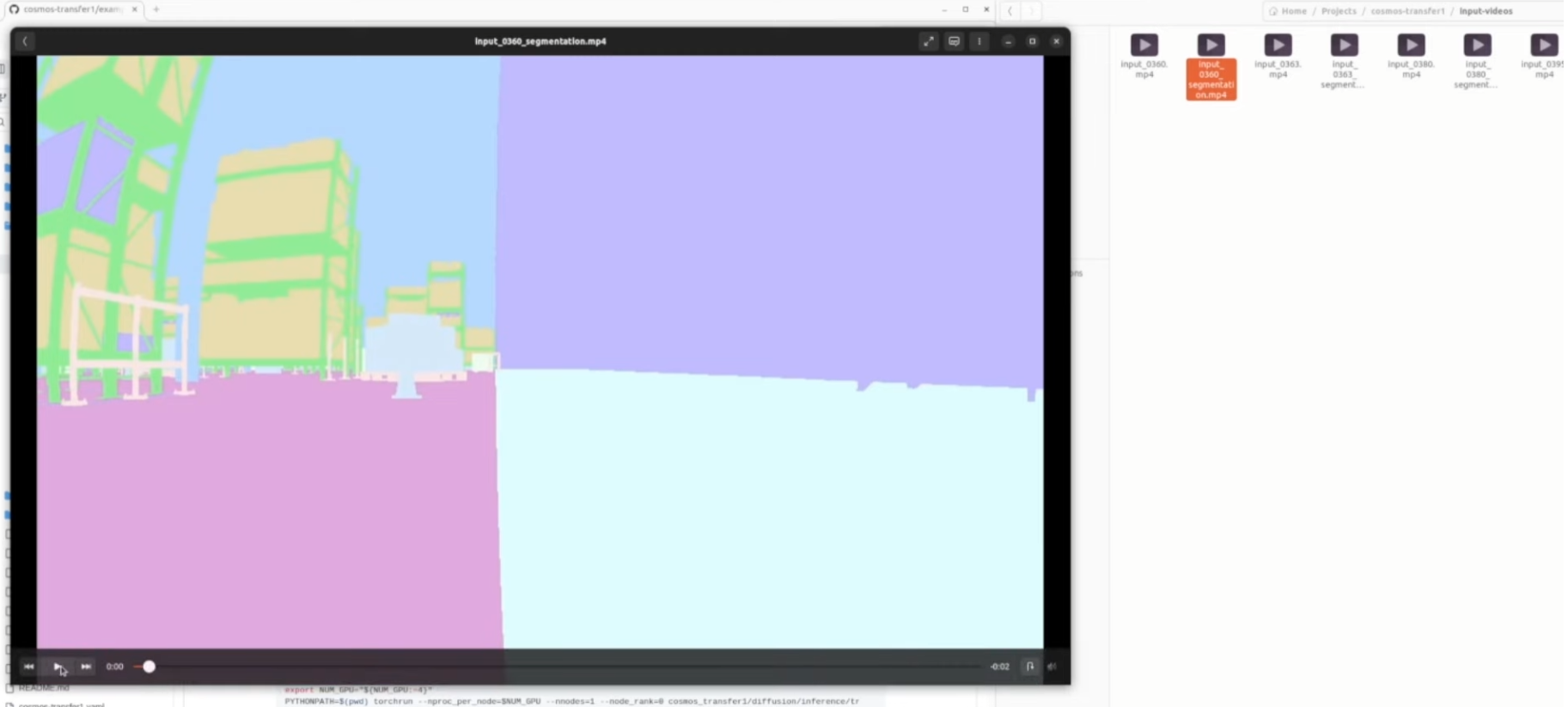
합성데이터 생성은 카메라 및 LiDAR 등 센서 기반 AI 모델을 학습시키기 위해 현실을 시뮬레이션으로 대체하여 대량의 레이블된 데이터를 자동 생성하는 과정이다.
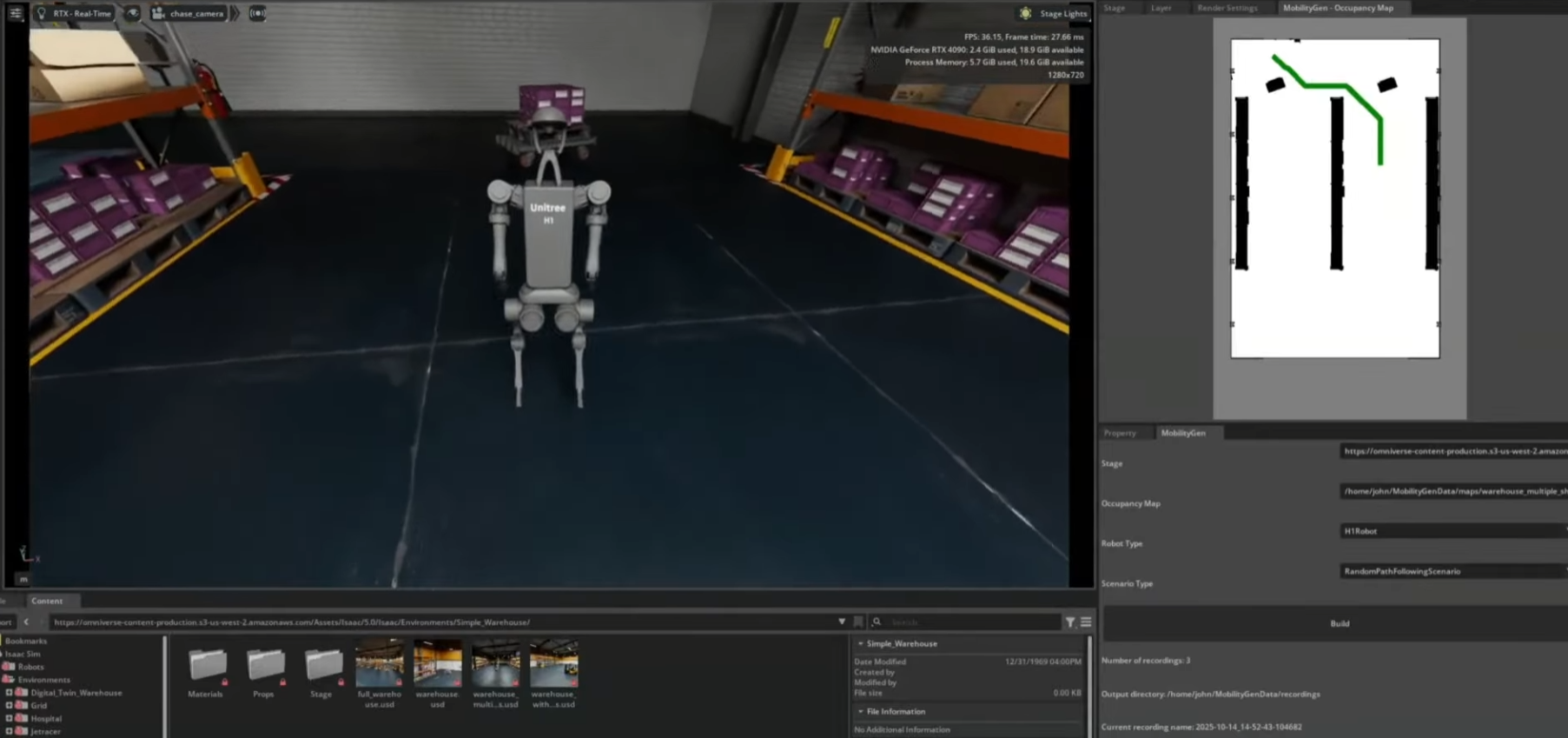
NVIDIA Isaac Sim은 이 합성데이터 파이프라인 전용 기능을 포함한다.
특징적으로, 합성데이터는 수동 라벨링 없이도 다음 데이터를 자동 생성할 수 있다.
합성데이터 생성이 필요한 이유
즉, 합성데이터는 로봇 Perception 학습에서 데이터 다양성, 규모, 난이도를 자유롭게 조절할 수 있는 핵심 기술이다.
3) Isaac Lab (Headless 학습 — 렌더링 없음)

Isaac Lab은 강화학습 및 로봇학습을 위해 Headless(비시각화) 실행이 가능하다.
따라서 아래 AI 전용 GPU도 Isaac Lab 학습에는 사용 가능하다.
Headless에서는 오직
플랫폼 고려사항: Isaac Lab의 JAX 기반 SKRL 학습은 aarch64 아키텍처(예: DGX Spark)에서 기본적으로 CPU-only로 실행되지만, JAX를 소스에서 빌드하면 GPU 지원이 가능합니다(현재 Isaac Lab에서 검증되지 않음).
Omniverse 기반의 디지털트윈/센서 시뮬레이션과 대규모 AI 학습은 사용하는 GPU 아키텍처가 서로 다르기 때문에 한 대의 GPU만으로 모든 워크로드를 해결하기는 어렵다.
단, 목적, 규모, 예산에 따라 다음 3가지 구성이 일반적으로 사용된다.
“단일 RTX GPU 워크스테이션 구성”
RTX 기반 GPU(예: RTX PRO 6000, RTX 6000 Ada)는 다음을 하나의 워크스테이션에서 동시에 수행할 수 있다.
특징
한계
이 구성에 적합한 GPU
결론
“Omniverse + 중간 규모 AI 작업까지 가능한 범용 개발 워크스테이션”
“RTX GPU + AI GPU 혼합 서버 구성”
이 구조는 실제 연구소, 기업에서 가장 많이 사용된다.
용도 분리
장점
서로 다른 GPU에서 최적 성능으로 실행
구성 예시
결론
“AI 학습 속도 + Omniverse 그래픽 성능을 모두 보장하는 가장 이상적인 아키텍처”
“서버 이원화(전용 서버 분리)”
완전히 분리하여 운영하는 방식.
장점
이 구성은 NVIDIA가 실제 기업·로봇고객에게 권장하는 공식 구조와 동일하다.
결론
“대규모 디지털트윈 + 로봇 AI 학습을 운영하는 엔터프라이즈 표준 구성”
NVIDIA Brev(Brev.dev)는 다양한 GPU 서버를 시간 단위로 대여하여 즉시 사용할 수 있는 클라우드 GPU 플랫폼이다.
GPU를 실제로 구매하기 전에, Omniverse/Isaac Sim/Isaac Lab이 어느 GPU에서 가장 잘 돌아가는지 실환경에 가깝게 테스트해야 할 때 매우 유용하다.
Brev는 특히 다음과 같은 케이스에 강점이 있다.
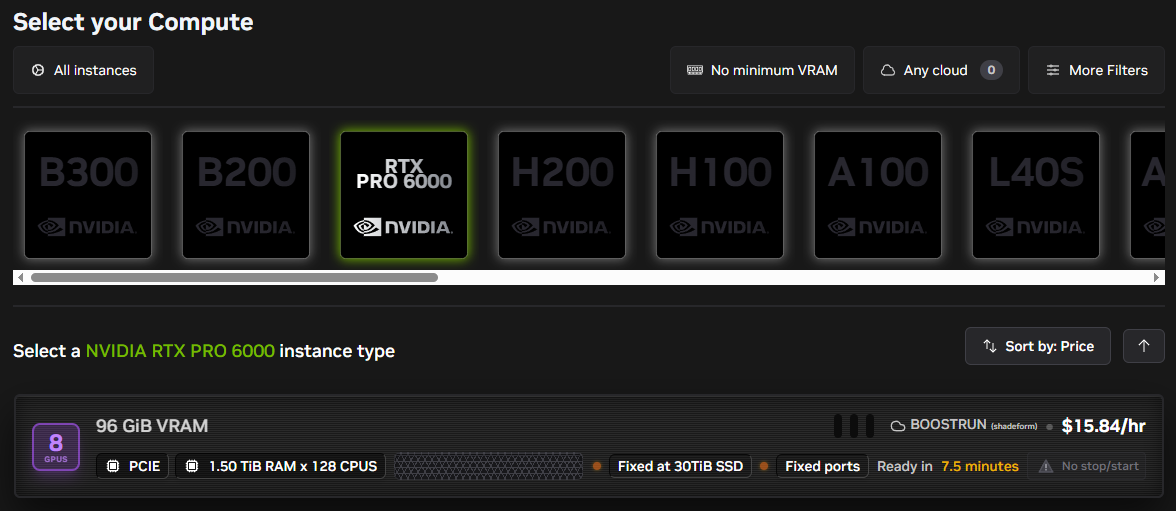
Brev는 공급자별로 제공되는 GPU가 달라지지만, 일반적으로 다음 GPU를 사용할 수 있다.
RTX 기반 (Omniverse 사용 가능)
AI 학습 전용 (Headless Isaac Lab 및 LLM 학습 가능)
즉, Brev는 “RTX 계열 + AI 계열”을 모두 제공하기 때문에 실제 로컬에서 구축하려는 서버 아키텍처를 클라우드에서 먼저 완전히 동일하게 실험할 수 있다.
이 글 공유하기:
| 완전 가능 |
| 가능 |
| Omniverse/로봇 시뮬레이션 최적, 96GB GDDR7 ECC, 24,064 CUDA Cores |
| L40S (Ada) | 있음 (3세대) | 가능 | 완전 가능 | 가능 | 데이터센터급 RTX 시뮬레이션/그래픽 최강, 48GB GDDR6 |
| L40 (Ada) | 있음 (3세대) | 가능 | 가능 | 가능 | Omniverse 가능한 워크스테이션/서버용, 48GB GDDR6 |
| RTX 6000 Ada | 있음 (3세대) | 가능 | 가능 | 가능 | 엔터프라이즈 워크스테이션용, 48GB GDDR6 |
| A6000 | 있음 (2세대) | 가능 | 가능 | 가능 | Ampere 세대 워크스테이션 강자, 48GB GDDR6 |
| A40 | 있음 (2세대) | 가능 | 가능 | 가능 | 서버용 RTX GPU, 48GB GDDR6 |
| A5000 | 있음 (2세대) | 가능 | 가능 | 가능 | 중급 RTX 기반 그래픽/시뮬 수행 가능, 24GB GDDR6 |