World Foundation Model(WFM)은 텍스트, 이미지, 영상 등 다양한 입력으로부터 현실 세계의 상태와 변화를 시퀀스 단위로 모사, 예측, 생성하는 대규모 모델이다.

WFM은 물리적 시뮬레이션(예:NVIDIA Cosmos)을 통해 로봇, 자율주행 등 Physical-AI 분야에서 합성 데이터 생성 및 환경 예측에 활용된다. 이 계열은 실제 센서, 로봇 동작, 자율주행 환경을 포함한 “World-as-Physics” 방향의 모델이다.

한편, DeepMind Genie 3, OpenAI Sora2 등은 세계의 물리 규칙뿐 아니라 시각적 인과성, 인지적 패턴, 언어적 맥락까지 학습하는 “World-as-Perception / Understanding” 계열의 WFM이다.
이들은 텍스트나 영상 입력만으로 환경의 변화를 시뮬레이션하거나 에이전트가 인지적으로 상황을 해석
하도록 학습한다.
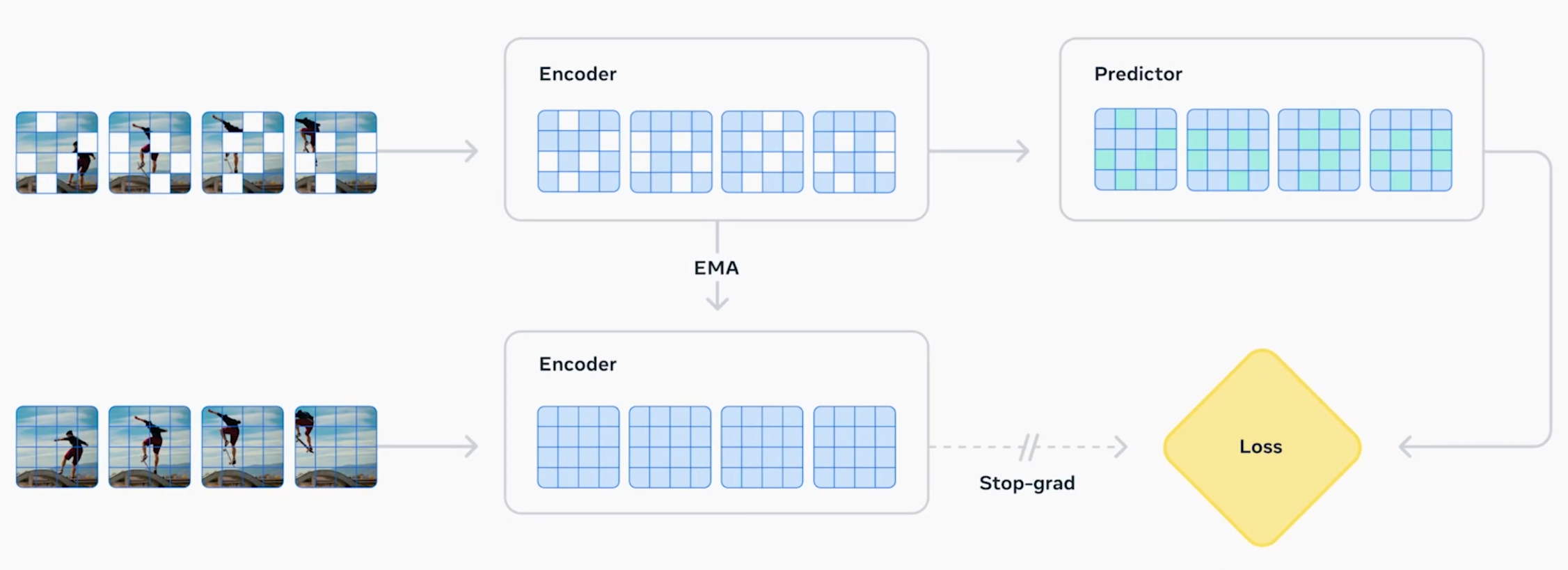
Meta V-JEPA 2는 영상의 일부 정보를 가리고 남은 프레임으로 미래 장면을 예측하는 비지도 자기학습 (Video self-supervised)모델이다. 화면의 공간, 시간적 패턴을 추론해 장면 이해와 행동 계획을 동시에 향상시키며, 이는 WFM 중에서도 “World-as-Prediction / Understanding” 방향을 대표한다.
| 구분 | 설명 |
|---|---|
| 핵심 개념 | WFM은 “세계를 단위로 이해하고 예측하는 범용 모델”로, 물리적 환경뿐 아니라 시각적·언어적·인지적(world understanding) 레벨의 구조를 학습한다. |
| 핵심 목적 | 세계의 상태를 모사(simulate), 예측(predict), 재구성(generate) 하여 AI가 상황을 맥락적으로 이해(contextual world modeling) 하도록 만드는 것. |
| 적용 영역 | 로봇/자율주행(물리 세계)뿐 아니라 비전-언어 모델, AI 에이전트(reasoning), 가상세계 생성(GenAI) 까지 확장. |
| 기술적 기반 | Vision Transformer, Diffusion, Video Generation, World Model Learning (Dreamer, PlaNet, Genie 계열) 등. |
| 구분 | 이름 | 특성 / 설명 | 관련 링크 |
|---|---|---|---|
| 플랫폼 / 통합 WFM | NVIDIA Cosmos | 물리 AI용 합성 데이터 생성 및 세계 예측 기능을 갖춘 WFM 플랫폼. Omniverse와 연계되어 로봇, 자율주행, 시뮬레이션용 데이터 생성 지원. | 관련 링크: NVIDIA Newsroom |
| 세계 생성형 | DeepMind Genie 3 | 텍스트 한 줄로 실시간 인터랙티브 월드를 생성. 월드 모델 연구의 대표적 생성형 접근. | 관련 링크: DeepMind Blog |
| 세계 생성형 | OpenAI Sora2 | 텍스트 입력으로 물리적 일관성을 유지하는 고해상도 비디오를 생성하는 모델. | 관련 링크: OpenAI Sora 공식 페이지 |
| 예측 / 이해형 | Meta V-JEPA 2 | 영상 자기지도 기반으로 장면 예측과 계획을 수행하는 세계 이해형 모델. | 관련 링크: Meta AI Blog |
한눈에 비교 차트 (2025 성능 기준, 공식 벤치마크)
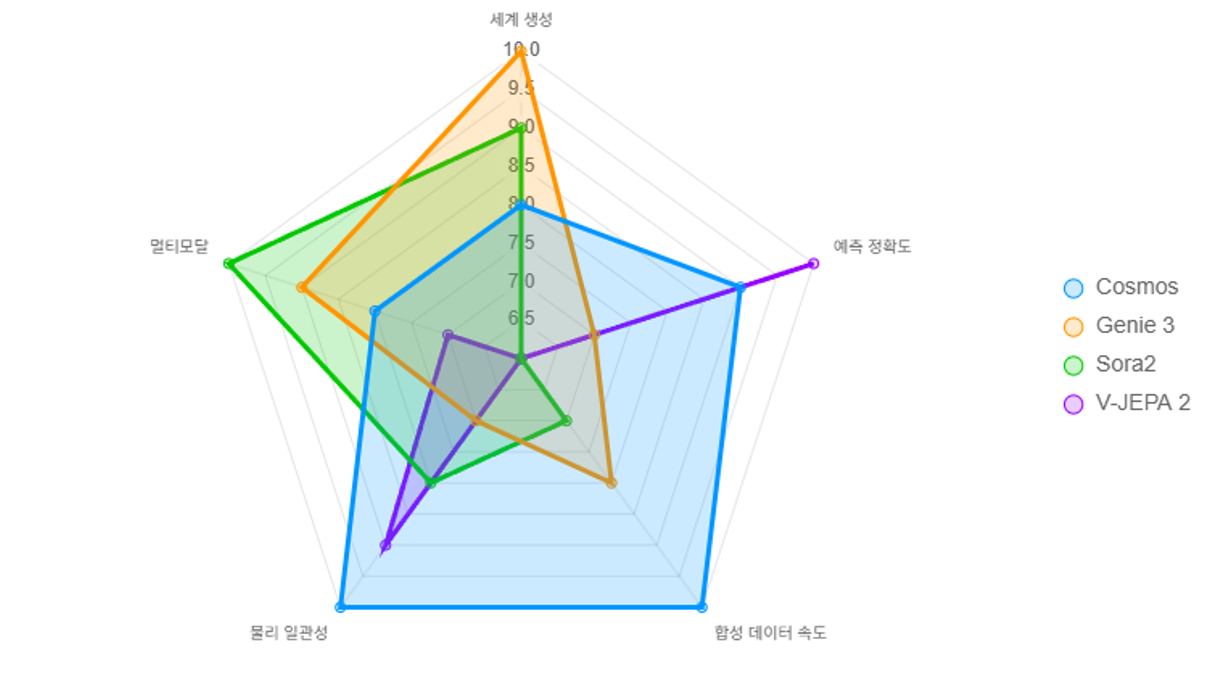
WFM은 단순한 비디오 생성기를 넘어선 개념이다.

“생성 + 이해 + 예측 + 합성 데이터 제공”이 모두 포함된 통합적 모델이다. 이 정의는 NVIDIA Cosmos 설명 문서에서도 반영되고 있다.
관련 자료:NVIDIA Announces Major Release of Cosmos World Foundation Models— NVIDIA Newsroom
WFM과 RFM(Robot Foundation Model)은 역할이 명확히 구분된다.
이 역할 구분은 Cosmos 논문에서도 “world model + policy model” 구조로 명시되어 있다.

위에 그림은 Cosmos 논문에 제시된 WFM의 기본 구조로, 과거의 관측값 x₀:ₜ 과 로봇의 행동 입력 cₜ 을 받아, 다음 세계 상태 x̂ₜ₊₁ 을 예측하는 과정을 보여준다.
이는 곧 WFM이 환경을 예측하고, RFM이 행동을 결정하는 구조적 관계를 시각적으로 설명한다.
(관련 논문: Cosmos World Foundation Model Platform for Physical AI — arXiv 관련 링크: arXiv)
이 구분은 WFM의 생성, 예측 중심 역할과 로봇 제어 중심 RFM의 역할 분리를 강조하는 구조적 관점에서 유용하다.
Omniverse / NVIDIA 환경과의 연결
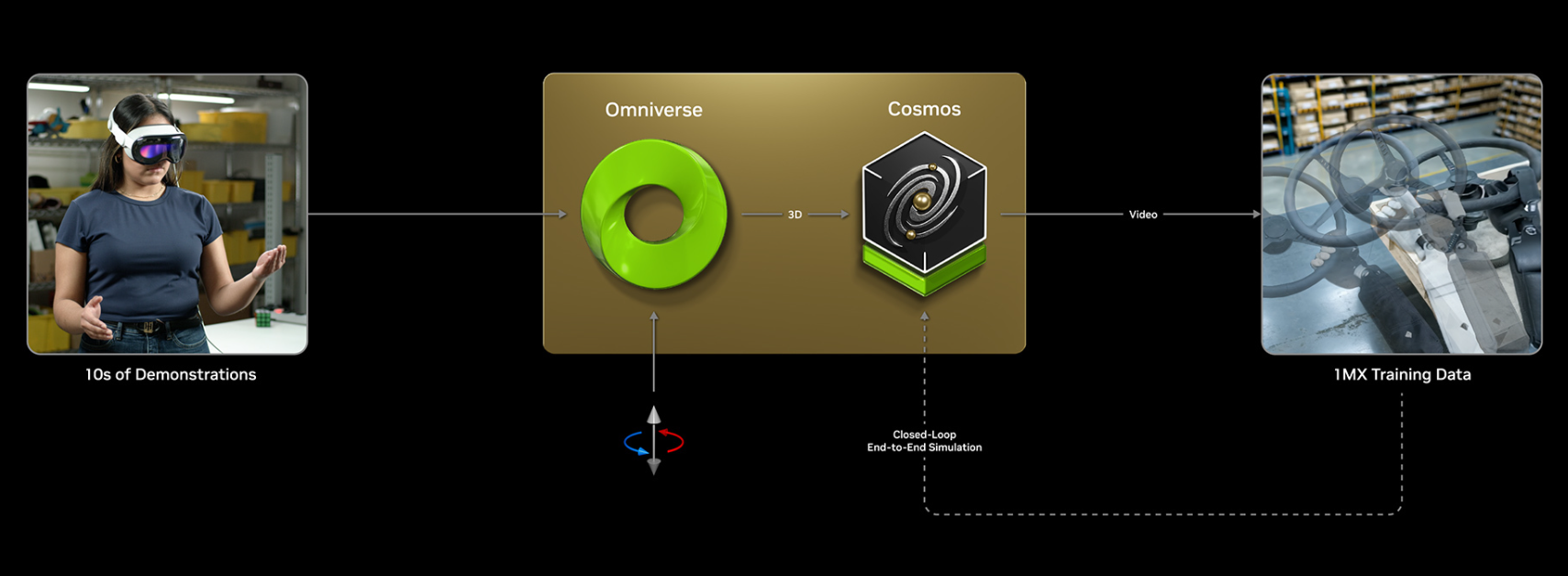
WFM, 특히 NVIDIA Cosmos,는 Omniverse 라이브러리와 함께 제공되어 다음 기능을 통합 지원한다.

또한, Omniverse Blueprints가 Cosmos WFM과 연결되어 로봇 준비 시설(robot-ready facilities)과 대규모 합성 데이터 생성을 가능하게 한다는 발표도 확인된다.

(관련 기사: NVIDIA Omniverse Physical AI Operating System Expands to More Industries and Partners)
WFM(World Foundation Model)은 단일 기업의 기술이라기보다, AI가 “세계를 이해, 예측, 생성”하는 공통 목표를 향한 범세계적 연구 트렌드다. 아래는 물리 중심의 WFM을 넘어, 인지, 시각, 언어 기반 세계 모델링으로 확장된 대표 흐름이다.
1. World-as-Generation (세계 생성 중심)
| 모델 | 개발 주체 | 핵심 개념 | 대표 활용 |
|---|---|---|---|
| DeepMind Genie 3 | Google DeepMind | 텍스트 한 줄로 1080p, 30fps 수준의 실시간 인터랙티브 월드 생성. 세계의 시각적 규칙과 상호작용을 비지도 학습. | 가상 환경 시뮬레이션, 비디오 기반 에이전트 학습 |
| OpenAI Sora2 | OpenAI | 텍스트 입력만으로 물리적으로 일관된 장면/시퀀스 비디오 생성. “세계의 인과 구조”를 영상으로 학습. | 미디어 생성, AI 비전 모델 프리트레이닝, 환경 합성 |
2. World-as-Perception / Understanding (세계 이해 중심)
| 모델 | 개발 주체 | 핵심 개념 | 대표 활용 |
|---|---|---|---|
| Meta V-JEPA 2 | Meta AI | 영상 일부를 가리고 미래 프레임을 예측하는 비지도 자기지도 학습(Self-supervised). 세계의 공간, 시간적 인과 구조를 내재적으로 학습. | 로봇 비전, 행동 계획, 예측 기반 인지 |
| Google VideoPoet | Google DeepMind (2025 통합) | 비디오, 오디오, 텍스트를 통합 처리하는 멀티모달 월드모델. 시간적 일관성과 맥락 기반 이해를 강화. | 영상 이해, 에이전트 예측, 스토리텔링 모델링 |
3. World-as-Physics (세계 시뮬레이션 중심)
| 모델 | 개발 주체 | 핵심 개념 | 대표 활용 |
|---|---|---|---|
| NVIDIA Cosmos | NVIDIA | 로봇, 자율주행, 산업 시뮬레이션용 물리 일관성 모델. Omniverse 기반 합성 데이터와 시뮬레이션 자동화. | 로봇 학습, 물리 기반 Sim-to-Real, 디지털 트윈 |
| PlaNet | DeepMind+ MIT 확장 | 환경의 물리적 법칙을 잠재공간(latent space)에서 모델링. 강화학습(RL)과 결합하여 정책 학습 강화. | 강화학습, 로봇 행동 제어, 환경 모델링 |
WFM이 다루는 데이터 스펙트럼은 단순한 시각, 물리 정보에 그치지 않는다.
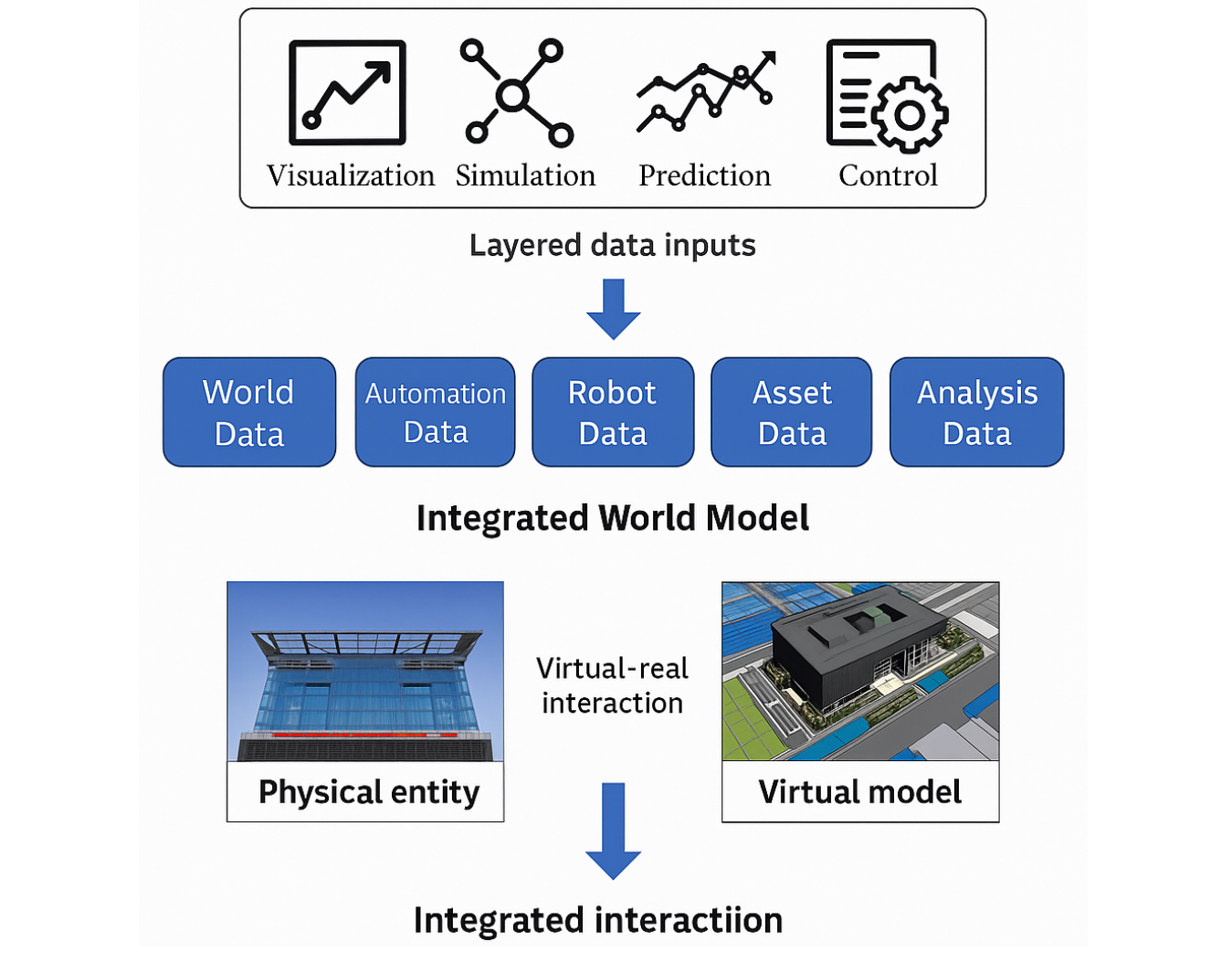
실제로 WFM은 World / Automation / Robot / Asset / Analysis Data의 다층 구조를 통합적으로 학습하며, 이를 통해 세계의 상태와 변화를 예측하는 ‘통합 세계 모델(Integrated World Model)’로 발전한다.
이 다섯 가지 데이터는 WFM의 입력 도메인을 구성하며, Cosmos, Genie, V-JEPA 등 각 모델은 특정 도메인(물리, 시각, 인지)에 집중하여 “세계를 이해하고 생성”하는 공통 목표를 지닌다.
다섯 가지 데이터 구조의 역할은 다음과 같다.
| 구분 | 주요 내용 |
|---|---|
| World Data | 물리적 환경, 시각적 장면, 시간, 공간적 변화 등 세계의 기본 상태를 구성하는 데이터 |
| Automation Data | 공정, 설비, 이벤트 시퀀스 등 자동화 시스템의 작동 흐름과 절차적 데이터 |
| Robot Data | 로봇의 센서, 동작, 제어 정책, 행동 로그 등 에이전트의 경험 기반 데이터 |
| Asset Data | 장비, 설비, 시설 자산의 상태, 유지보수, 활용 정보 등 디지털 트윈과 연계되는 데이터 |
| Analysis Data | 상위 데이터로부터 도출되는 통합 인사이트 및 피드백 데이터, 모델 학습에 재투입되는 정보 |
이 다층 데이터 구조는 WFM이 세계를 이해하고 시뮬레이션하는 입력 기반으로 작동하며,
결과적으로 AI가 “맥락적 세계 인식(Contextual World Modeling)”을 수행할 수 있도록 돕는다.
이 글 공유하기: