실습 가이드: GR00T‑Mimic 원격 시연 로드 + 어노테이션
핵심 메세지
원격 시연 데이터를 통해 로봇 작업별 하위 작업 종료 시점을 정의하고 학습 데이터를 생성하는 방법
내용 요약
1단계: 원격 시연 데이터 로드하기
- Isaac Sim 내 로봇(예: GR‑1) 시연 데이터 로드
- 최초 상태: 로봇은 Idle 상태로 대기
- 로드된 시연 데이터를 통해 로봇 작업 진행 가능
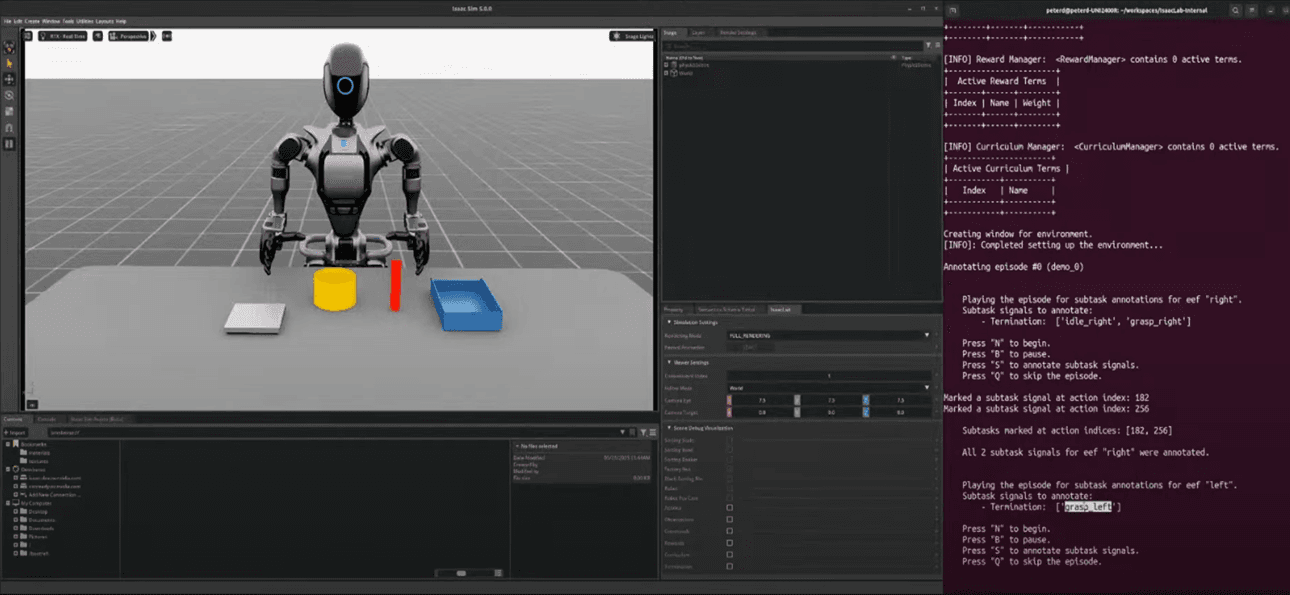
2단계: 궤적 재생 & 종료 시점 표기
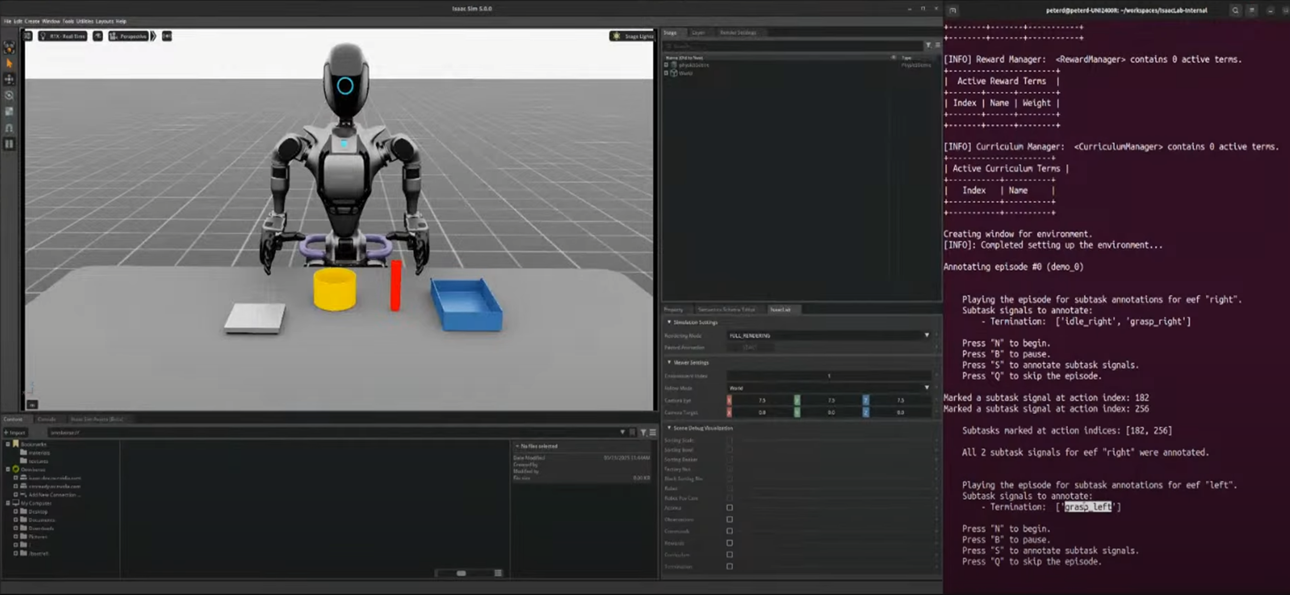
- N 키: 원격 시연 궤적 재생 시작
- B 키: 재생 일시 정지 가능
- S 키: 현재 하위 작업 종료 시점을 표기
- 예: 오른팔 작업 (Idle → Grasp) 종료 시점 표기
- 예: 왼팔 작업 (Grasp → Place) 종료 시점 표기
- 마지막 작업 종료 시점은 암묵적으로 정의 (별도 표기 불필요)
3단계: 원격 시연 예시
- 오른팔 작업:
- 최초 상태: Idle
- 작업: 첫번째 하위 작업(예: 물체 잡기) 종료 시점 표기
- 왼팔 작업:
- 최초 상태: Idle
- 작업: 비커 잡기 후 종료 시점 표기
- 마지막 작업은 자동으로 종료 시점 정의
4단계: 자동화된 데이터 생성
- 표기된 종료 시점을 통해 GR00T‑Mimic이 데이터를 학습 가능 포맷으로 변환
- 높은 정밀도 필요 없으며, 대략 종료 시점을 표기해도 충분
- GR00T‑Mimic 인터폴레이션 기능이 로봇 학습 데이터를 강인하고 원활하게 생성
Isaac Lab Teleoperation and Imitation Learning 참고 링크
https://isaac-sim.github.io/IsaacLab/main/source/overview/teleop_imitation.html
실습 가이드: GR00T‑Mimic 데이터 생성 & 재생
핵심 메세지
원격 시연 데이터를 통해 로봇 작업별 하위 작업 종료 시점을 정의하고 학습 데이터를 생성하는 방법
내용 요약
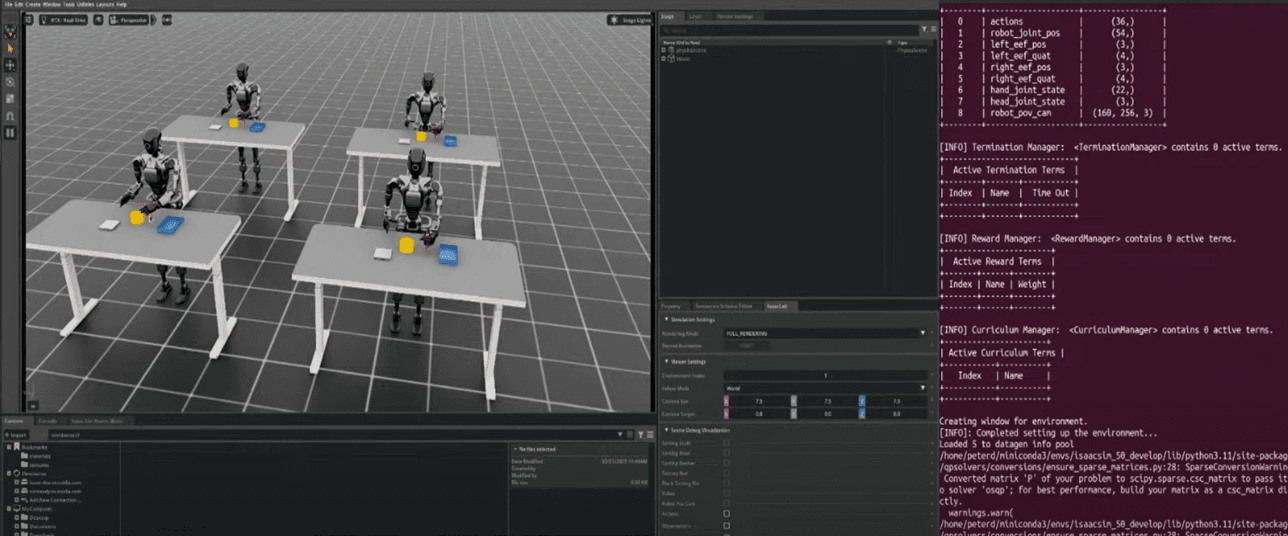
1단계: 데이터 생성 실행
- 터미널에서 아래 명령어 실행
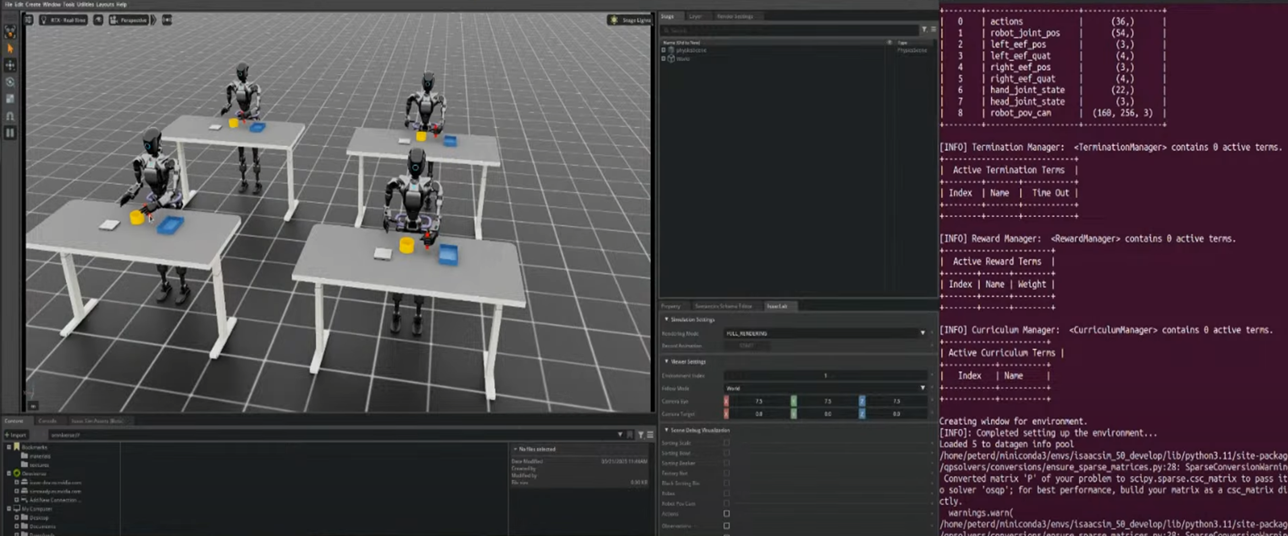
- python run_data_generation.py --num_envs 4
- 이렇게 4개의 병렬 환경에서 데이터 생성 가능
- 원하면 -num_envs 값을 변경해 병렬 개수를 조절 가능
2단계: 동작 시뮬레이션
- 생성 과정 중 로봇은 원래 동작 외에도 랜덤 액션 노이즈를 추가
- 로봇 팔이 살짝 흔들리는 것이 보일 수 있음
- 학습된 모델은 이러한 변동 속에서 강인성을 갖도록 학습 가능
- 원하면 노이즈 강도 변경 가능 (--noise_level 같은 파라미터 활용)
3단계: Headless 모드 활용
- 대규모 데이터 생성 시 전체 Isaac Sim 시각화 대신 headless 모드로 실행 가능
- 성능 증가
- python run_data_generation.py --num_envs 100 --headless
4단계: 생성된 데이터 재생
- 생성된 데이터를 시각화해 품질 체크 가능
- replay_data.py 스크립트 실행
- python replay_data.py --dataset_dir path/to/dataset
- 로봇의 원래 동작뿐 아니라, 액션 노이즈가 추가된 데이터를 함께 재생 가능
- 병렬 환경 수도 지정 가능 (--num_envs)
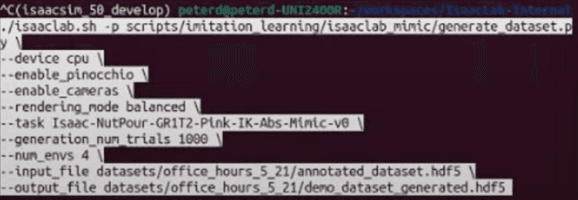
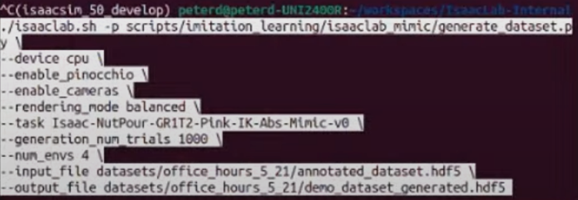
- -generation_num_trials 1000
- 생성하고자 하는 데이터셋의 전체 시도(샘플) 수를 의미
- 즉, 1000개의 데이터를 생성하겠다는 뜻
- -num_env 4
- 데이터를 생성하는 동안 동시에 병렬로 실행될 환경(시뮬레이션) 수를 의미
- 1000개의 데이터를 한 개의 환경에서 생성하면 매우 오래 걸림
- 하지만 4개의 병렬 환경(--num_env 4)을 통해 한 번에 4개의 데이터를 생성하므로
- 속도가 4배 빨라질 수 있음
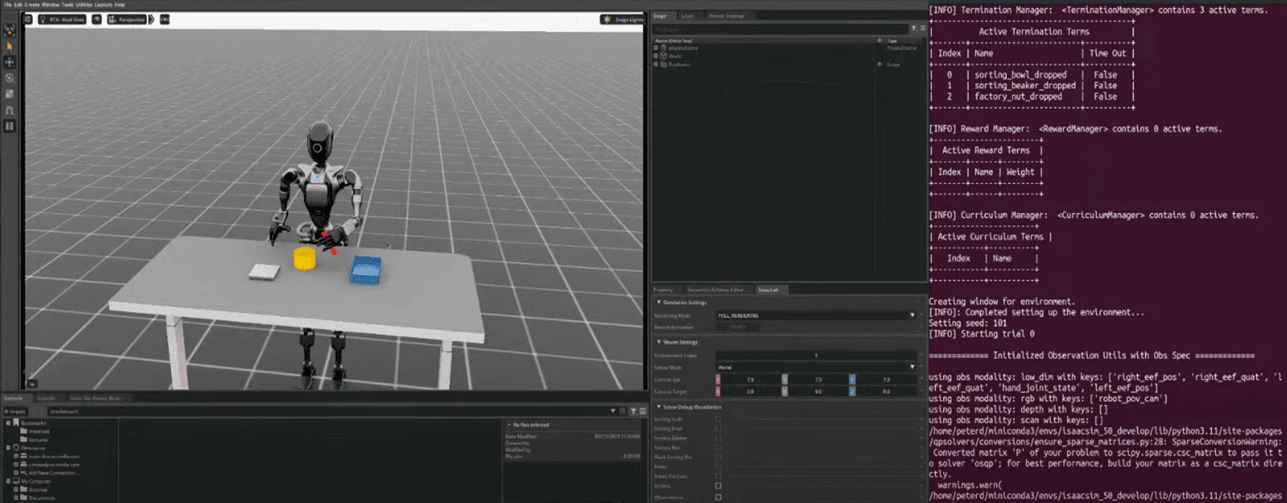
실습 가이드: GR00T‑Mimic 학습된 정책
핵심 메세지
원격 시연 데이터를 통해 로봇 작업별 하위 작업 종료 시점을 정의하고 학습 데이터를 생성하는 방법
내용 요약
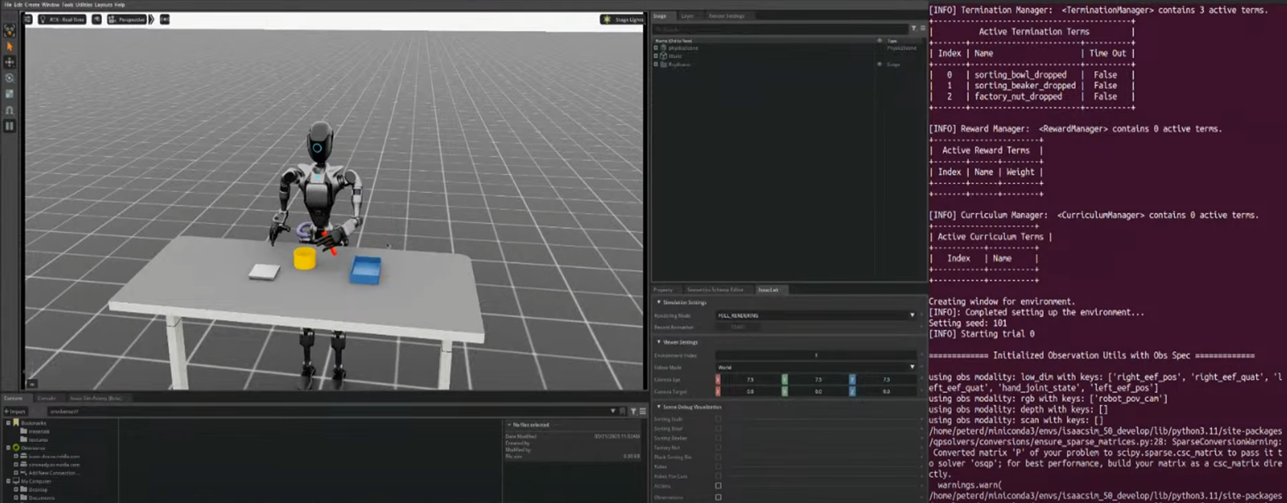
1단계: 생성된 데이터를 통해 로봇 정책 학습
- 원격 제어로 로봇 시연 데이터를 수집 후,
- 생성된 데이터셋(예: 1000개의 시연)을 통해 로봇 학습 진행
- 학습된 정책은 LSTM 정책으로 학습
LSTM (Long Short‑Term Memory)정책
- 시계열 데이터를 학습하는데 강점이 있는 RNN의 한 종류
- 로봇 제어에서는 연속된 동작(예: 물건 잡기 → 이동하기 → 내려 놓기)처럼
- 시간적 연관이 있는 데이터를 학습하는데 사용
2단계: 학습된 정책의 성능
- 학습된 정책은 원래 로봇 시연 데이터뿐 아니라 생성된 랜덤 데이터를 통해 강인성을 확보
- 로봇은 학습 후 원래 있던 ‘행동 떨림(Action Noise)’이 거의 나타나지 않음
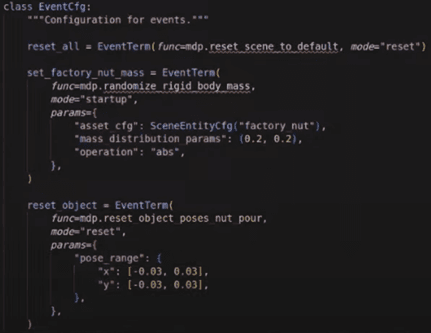
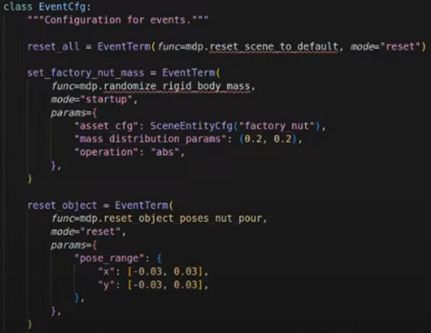
3단계: 랜덤화 가능 범위 제어
- 학습 환경 내 로봇 작업 물체의 위치 랜덤화 가능
- 원래 시연과 동일한 데이터를 통해서도 랜덤화 범위 변경 가능
- 예: 원래 시연보다 랜덤화 범위를 더 넓혀서 학습 가능
- 원래 시연보다 랜덤화 범위를 너무 많이 늘리면 성능 저하 가능
- 일정 범위 내에서 랜덤화 가능
- 너무 큰 랜덤화는 원래 시연과 학습된 데이터 사이의 불일치로 실패 가능