Robot Foundation Model은 로봇이 시각, 언어, 행동 데이터를 통합적으로 학습하여, 다양한 형태와 과제에 일반화된 행동지능을 발휘하도록 설계된 거대 모델이다. 인간의 ‘상식적 물리 이해 + 목표 지향 행동’을 모방하면서, 특정 로봇이나 태스크에 국한되지 않고 범용적인 스킬 전이를 가능하게 한다.

RFM은 WFM이 만들어낸 ‘물리적으로 일관된 상상세계’를 학습의 장으로 사용한다. 그 안에서 수천, 수만 가지의 시뮬레이션 상황을 경험하며, 행동정책(policy)과 전략을 연마한다. 결국 RFM은 현실세계에서의 물리적 제약을 인식하고, 다양한 목표에 맞춰 능동적으로 행동하는 행동지능의 총체가 된다.
RFM의 1차 목표는 다양한 로봇 형태와 환경에서도 일관된 행동 원리를 학습이다.
즉, 특정 로봇이나 특정 과제에 고정된 정책이 아니라, 다양한 형태의 로봇(팔, 다리, 모바일, 휴머노이드 등)과 다양한 태스크(조작, 이동, 협업 등)에 공통적으로 적용 가능한 행동 표현(behavior representation) 을 만드는 것이다.
조금 더 깊게 들어가면, RFM의 최종 목표는 “행동 그 자체”가 아니라 의도(intent)와 목적(goal) 을 물리적 세계에서 실현하는 능력이다.


RFM은 시각(Perception), 언어(Language), 행동(Action)을 통합한 “Perception–Reasoning–Action Loop” 구조를 가진다.
로봇은 환경으로부터 입력된 관측값을 해석하고(Perception), 언어적 명령이나 목표를 이해한 뒤(Language Reasoning), 행동정책(Policy Model)을 통해 실제 동작(Action)으로 연결한다.
이 과정은 다음의 기술적 프레임워크를 기반으로 한다.
| 구성 단계 | 주요 기술 기반 | 설명 |
|---|---|---|
| Perception (인식) | Vision Transformer, 3D Point Cloud Encoder, RGB-D Fusion | 카메라 및 센서 데이터를 통해 장면과 객체 상태를 인식 |
| Reasoning (이해/계획) | LLM 기반 Goal Parsing, Graph Transformer | 언어적 명령과 시각 정보를 통합하여 행동 계획 생성 |
| Action / Policy (행동) | Diffusion Policy, Reinforcement Learning, Imitation Learning | 물리 제약 내에서 최적의 행동정책을 실행 |
관련 자료:GR00T N1: An Open Foundation Model for Generalist Humanoid Robots — arXiv (2025)
관련 자료:π₀: A Vision-Language-Action Flow Model for General Robot Control — arXiv (2024)
RFM은 WFM(World Foundation Model)이 생성한 ‘물리적으로 일관된 가상 세계(Consistent Virtual World)’를 학습의 장으로 사용한다.

즉, WFM이 “무엇이 일어날지 (What happens next)”를 예측한다면, RFM은 “무엇을 해야 하는가 (What to do next)”를 결정한다.
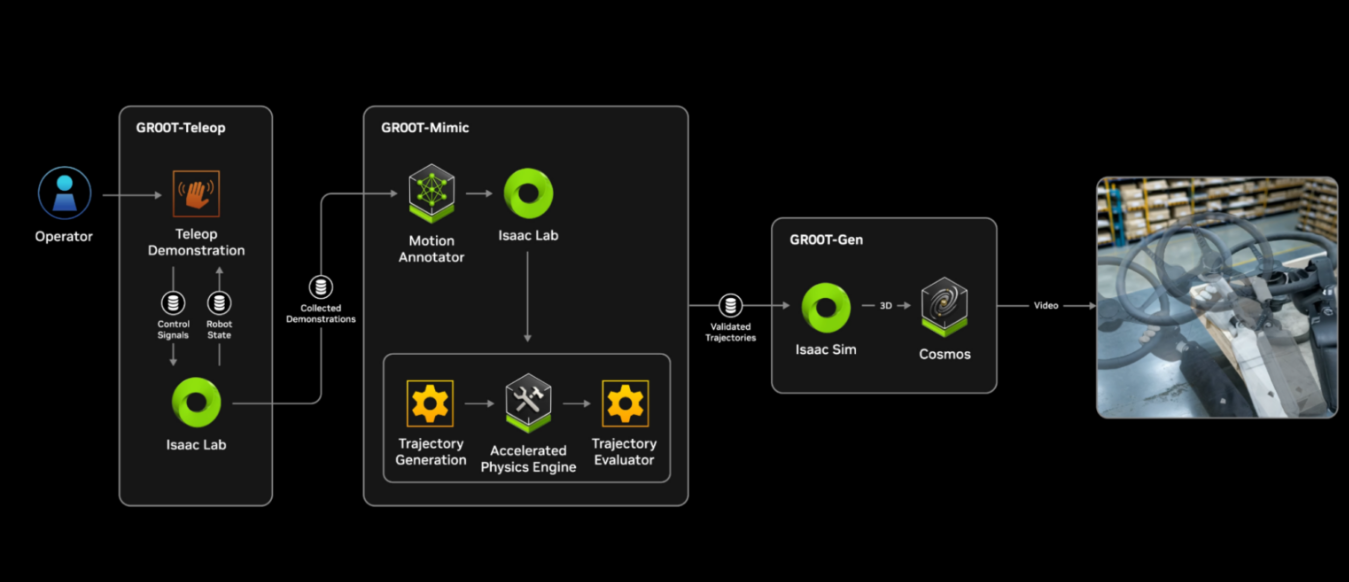
이 두 모델의 결합은 “Perception → Simulation → Action”의 완전한 인지–행동 루프(Perception–Action Loop)를 형성하며, AI가 시뮬레이션에서 학습한 정책을 현실 로봇에 이식(Sim-to-Real)할 수 있도록 돕는다. 이러한 구조는 실제로 NVIDIA Cosmos (WFM) 과 NVIDIA GR00T (RFM) 간의 설계 철학으로 이어진다. 즉, Cosmos가 세계의 물리적 법칙을 예측하고 시뮬레이션하는 반면, GR00T는 그 환경 안에서 로봇의 행동정책을 학습하여 현실 환경으로 전이한다.
관련 자료:NVIDIA Newsroom — “Isaac GR00T N1 and Cosmos: A Unified Physical AI Framework” (2025)
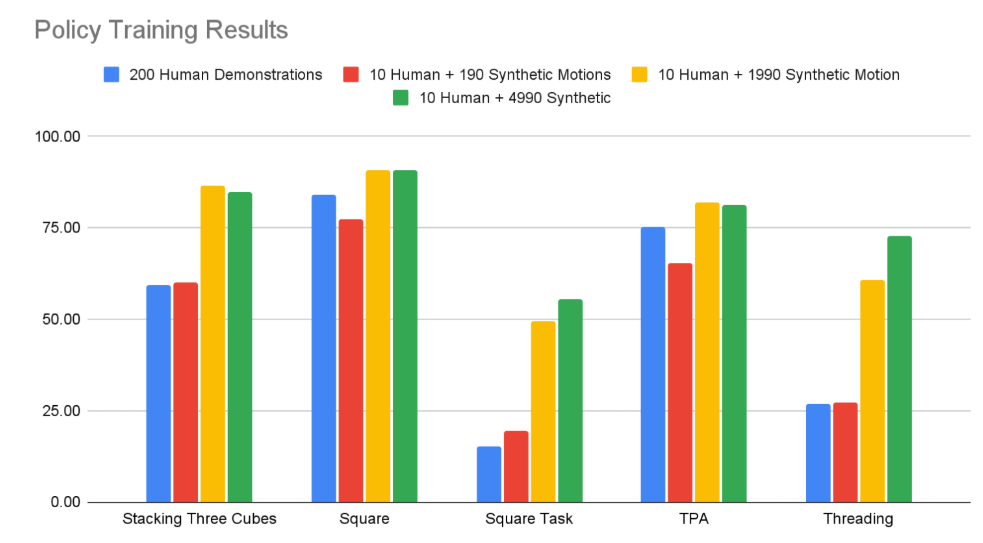
GR00T는 합성 모션(Synthetic Motion) 학습 파이프라인을 통해, 인간의 실제 시연 데이터를 증강해 대규모 모방 학습을 수행한다.
이 과정에서 수천 개의 인공 동작 데이터를 생성하여, 적은 수의 인간 시연만으로도 정책 학습 성능을 극적으로 향상시킬 수 있다.
관련 자료:NVIDIA Developer Blog — Building a Synthetic Motion Generation Pipeline for Humanoid Robot Learning
RFM은 WFM과 결합되어 다양한 산업 현장에서 지능형 행동 정책 학습 모델로 확장될 수 있다.

| 분야 | 주요 적용 예시 |
|---|---|
| 제조 및 물류 | 로봇팔 조립, 피킹/플레이스, 자동화 라인 제어 |
| 모빌리티 | 자율주행 로봇, 동적 장애물 회피, 실내 내비게이션 |
| 휴머노이드 / 서비스 로봇 | 인간-로봇 협업, 제스처 기반 상호작용, 환경 반응형 행동 |
| 연구 / 교육 | 로봇 정책 연구, 강화학습 실험, 시뮬레이션 검증 플랫폼 |
RFM은 현재 여러 연구기관 및 글로벌 기업에서 범용 로봇 행동 모델(Fundamental Robot Models) 개념으로 연구 중이다.

| 구분 | 모델 | 개발 주체 | 핵심 특징 | 대표 적용 |
|---|---|---|---|---|
| 행동 통합형 | GR00T N1 | NVIDIA | Vision-Language-Action 구조 기반, 휴머노이드 지원 | 물체 조작, 보행 등 |
| 대규모 데이터형 | RT-X / RT-2 | DeepMind + Google Robotics | 대규모 행동 데이터 통합 학습 | 다중 플랫폼 행동 |
| RL 융합형 | π₀ (pi-zero) | Physical Intelligence | Vision-Language-Action Flow + RL 통합 모델 | 범용 정책 학습 |
| 3D 조작형 | FP3 | CMU / MIT | 포인트클라우드 기반 3D 조작 전략 | 로봇팔, 조작 모델 |
| 시뮬레이션 확장형 | NVIDIA Genesis-2 | NVIDIA Research | 초고속 시뮬레이션 엔진 + 합성 데이터 생성 | Sim-to-Real 학습 확대 |
관련 자료:Robotics Startup Raises $105M to Build AI Model for Robots — Genesis AI
RFM은 단순히 로봇 행동 정책을 학습하는 모델을 넘어, 언어, 시각, 행동을 통합한 물리적 사고(Physical Reasoning) 를 수행하는 모델로 진화할 것이다.
향후 연구 방향은 다음과 같다.
언어, 시각, 음성, 촉각 등 복수 센서 모달리티의 통합적 이해
로봇 형태나 환경 변화에 따라 자동으로 스킬 전이하는 능력
현실 피드백을 통해 지속적으로 행동정책을 갱신
환경의 물리 법칙, 인과 관계를 스스로 이해하고 활용
여러 로봇 간 협업, 분담 및 공동 목표 수행을 위한 행동 정책 발전
이 글 공유하기: