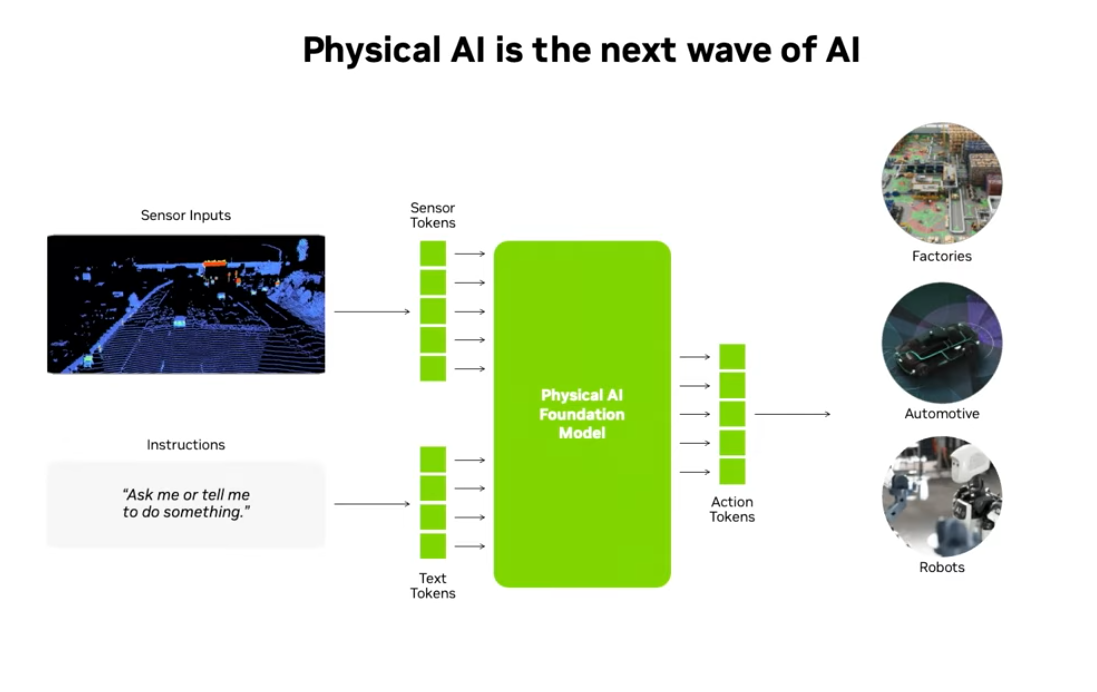
Isaac Lab 2.3.0 delivers major advancements across the entire robot-learning stack, introducing new workflows in areas such as humanoid manipulation and locomotion, integrated mobility control, an expanded imitation-learning pipeline, and Dexterous RL. This release is designed to make Physical AI development for real-world robotic systems easier, more scalable, and more consistent than ever.
Bar
DexSuite is a high-level reinforcement learning suite designed for learning dexterous manipulation tasks such as rotating, repositioning, and lifting objects. It is built to generalize robustly across diverse object shapes and physical conditions, enabling reliable performance even in complex manipulation scenarios.
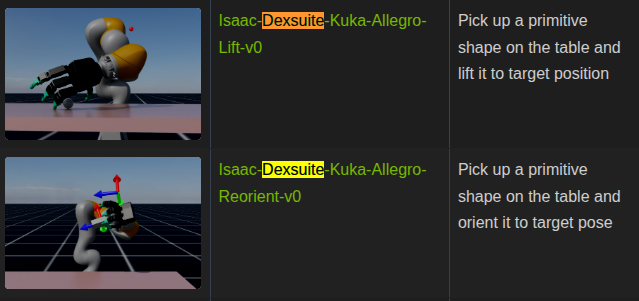
DexSuite is an environment for learning dexterous manipulation.
This environment aims to learn complex hand manipulation in simulation and transfer it to real robots.
Dex Environments
Following DextrAH and DexPBT, a new DexSuite has been added, including proficient Lift and Reorient environments. These environments also demonstrate the use of automatic domain randomization (ADR) and PBT (population-based training).


In Isaac Lab 2.3.0, the surface gripper has been extended to support the manager-based workflow.
This includes the addition of SurfaceGripperAction and SurfaceGripperActionCfg, as well as several new environments showcasing teleoperation use cases using surface grippers and the RMPFlow controller. New robots and variants have been introduced, including Franka and UR10 equipped with Robotiq grippers and suction cups, as well as Galbot and Agibot robots.
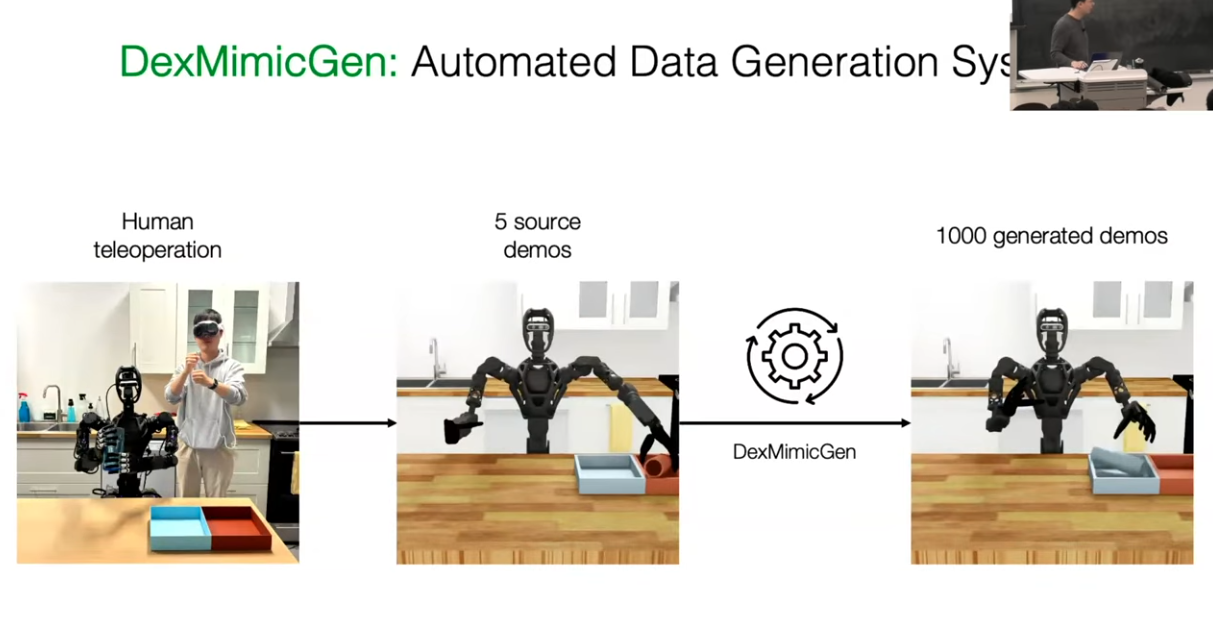
Support for SkillGen has been added to the Mimic imitation-learning pipeline, integrating with cuRobo and enabling GPU motion planning and skill-segmentation dataset generation. Since cuRobo is distributed under a proprietary license, please review the terms carefully before use.
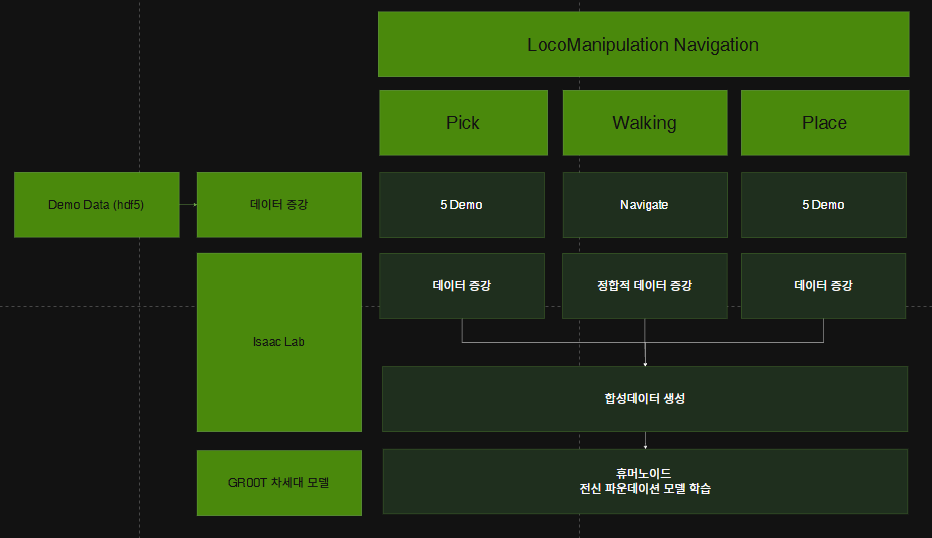
A new G1 humanoid environment has been added that combines reinforcement learning (RL)–based locomotion with IK-based manipulation. To complement demonstrations, the full robot navigation stack is integrated, with randomization of tabletop pick/place positions, destinations, and ground obstacles. By decomposing tasks into pick–navigate–place phases, this approach enables the generation of large-scale locomotion-manipulation datasets from manipulation-only demonstrations.
A new locomotion-manipulation G1 environment with upper- and lower-body controllers has been added. This allows control of the arms and fingers for demonstrations, while locomotion is realized by controlling the instantaneous pelvis velocity and height (vx, vy, wz, h). In addition, the Pink-based inverse kinematics controller now supports null-space pose regularization, enabling activation of the waist DOFs and expanding the reachable workspace of the humanoid.

The upper-body inverse kinematics controller has been improved by adding null-space posture tasks, enabling waist motion in humanoid tasks and regularizing toward an upright posture that favors desirable degrees of freedom. Support for Vive and Manus Gloves has also been added, providing more options for teleoperation devices.
Through navigation and demo augmentation, these in-field manipulation tasks can now be extended to generate large-scale pick–navigate–place datasets from manipulation-only demonstrations.
Step 1: dataset_annotated_g1_locomanip.hdf5 → generated_dataset_g1_locomanip.hdf5
Key Change: Augmentation of Static Manipulation Data
Additional Data:
# Randomly place the object
new_obj_pose = randomize_object_position()
# Location: data_generator.py:531
action_noise = subtask_configs[subtask_ind].action_noise
Change in Data Structure:
# Before (annotated)
{
"demo_0": {
"actions": [28 dimensions], # hand pose + joints
"states": {...}, # fixed object position
"subtask_boundaries": [0, 60, 130, 200] # subtask boundaries
}
}
# After (generated)
{
"demo_0": {
"actions": [28 dimensions], # modified hand pose
"states": {...}, # new object position
"subtask_boundaries": [0, 60, 130, 200] # same boundaries
},
"demo_1": {...}, # different object position
"demo_2": {...}, # different table position
...
"demo_999": {...} # 1,000 variants
}
Summary of Changes:
Step 2: generated_dataset_g1_locomanip.hdf5 → generated_dataset_g1_locomanipulation_sdg.hdf5
Key Change: Combining Static Manipulation with Locomotion
Additional Data:
# Location: generate_data.py:428
output_data.base_velocity_target = torch.tensor([linear_velocity, 0.0, angular_velocity])
# Location: generate_data.py:585-586
output_data.base_goal_pose = base_goal.get_pose()
output_data.base_goal_approach_pose = base_goal_approach.get_pose()
# Location: generate_data.py:590-594
output_data.obstacle_fixture_poses = torch.cat(obstacle_poses, dim=0)
# Location: generate_data.py:319, 367, 426, 480, 541
output_data.data_generation_state = int(LocomanipulationSDGDataGenerationState.NAVIGATE)
output_data.recording_step = recording_step # tracking original data step
Change in Data Structure:
# Before (generated – static manipulation)
{
"demo_0": {
"actions": [28 dimensions], # only hands + joints
"states": {
"base_pose": [fixed], # no change
"object_pose": [...]
}
}
}
# After (locomanipulation_sdg – dynamic locomanipulation)
{
"demo_0": {
"actions": [28 dimensions + base velocity], # hands + joints + locomotion
"states": {
"base_pose": [changing], # moving base
"object_pose": [...],
"base_path": [...], # added path info
"base_goal_pose": [...], # added goal pose
"obstacle_fixture_poses": [...] # added obstacles
},
"locomanipulation_sdg_output_data": {
"data_generation_state": 2, # NAVIGATE state
"base_velocity_target": [vx, 0, vyaw], # added locomotion command
"recording_step": 130 # tracking original step
}
}
}
Summary of Changes:
1. dataset_annotated_g1_locomanip.hdf5 → generated_dataset_g1_locomanip.hdf5
Meaning: Expanding a small number of expert demos into a large training dataset
The original dataset contains only five teleoperation demos, which is insufficient for training. In the data-generation stage, demos are decomposed into subtasks, object and environment positions are varied, and only physically valid variations are selected, resulting in 1,000 demos.
The key idea is to preserve relative relationships. For example, the relationship “the hand is 10 cm away from the object” is preserved even when the object position changes. This allows the model to learn identical manipulation patterns across many positions.
As a result, the robot learns to manipulate objects based on their relative relationship to the hand, instead of relying on absolute positions.
2. generated_dataset_g1_locomanip.hdf5 → generated_dataset_g1_locomanipulation_sdg.hdf5
Meaning: Extending static manipulation with locomotion to achieve locomanipulation
The second transformation adds locomotion components to static manipulation data. In the original data, the base is fixed; in the SDG stage, base motion is added while preserving the manipulation trajectories.
The key is joint control of manipulation and locomotion. The robot grasps and lifts the object, then moves while holding it, and finally places it at a target location. This process involves path planning, obstacle avoidance, and balance maintenance during movement.
A state machine manages the phases: grip → lift → navigation → approach → place. At each phase, the manipulation trajectory is preserved while locomotion commands are added. This allows the model to learn stable manipulation patterns even during movement.
As a result, the robot acquires locomanipulation capabilities — performing manipulation and locomotion simultaneously.
3. Overall Philosophical Meaning of the Transformations
Meaning: Converting limited human expert demos into robot-usable knowledge across diverse situations
The first transformation is about spatial generalization. Originally, the policy works only in specific poses; after transformation, it can operate over a wide range of positions.
The second transformation is about capability expansion. It extends from static manipulation to locomotion-augmented manipulation, enabling more complex tasks.
Overall, this pipeline converts limited, situation-specific human demos into generalized and expanded knowledge that robots can apply in many scenarios.
1. Structural Meaning of the Unified Action Space
Physical composition of the action vector:
# Location: g1_locomanipulation_sdg_env.py:180-233
action = [
left_hand_pose[7], # left hand position + orientation (manipulation)
right_hand_pose[7], # right hand position + orientation (manipulation)
left_hand_joints[12], # left hand joints (manipulation)
right_hand_joints[12], # right hand joints (manipulation)
base_velocity[3] # base velocity [vx, 0, vyaw] (locomotion)
] # total 41-dimensional unified action vector
Important point: The neural network predicts both manipulation and locomotion from a single output vector. This is fundamentally different from training them separately.
2. Learning Meaning of Preserving Manipulation Trajectories
Why preserve manipulation trajectories while adding locomotion?
A. Learning Relative Relationships
The network learns the pattern: “even as the base moves, the relative relationship between hand and object is preserved.”
Pattern in the training data:
Time 1: base (0, 0), hand (1, 0, 0.5), object (1.2, 0, 0.5)
Time 2: base (0.5, 0), hand (1.5, 0, 0.5), object (1.7, 0, 0.5)
What the network learns:
If the manipulation trajectory is also changed:
B. Consistent Learning Signals
By preserving manipulation trajectories, the network receives a clear signal: “manipulation patterns stay the same; only locomotion is added.”
Training process:
Input: [base pose, object pose, goal pose, ...]
Output: [hand pose, hand joints, base velocity]
Learned mapping:
- Base pose changes → base velocity changes
- Object pose changes → hand pose changes (relative relationship preserved)
- Synchronization between base velocity and hand pose
3. Difference Between Joint and Separate Training
Separate Training (if manipulation and locomotion were learned independently):
# Manipulation policy
manipulation_policy(obs) → [hand_pose, hand_joints]
# Locomotion policy
locomotion_policy(obs) → [base_velocity]
Issues:
Joint Training (current approach):
# Unified policy
locomanipulation_policy(obs) → [hand_pose, hand_joints, base_velocity]
Advantages:
4. Internal Learning Mechanism of the Network
Hidden patterns learned by the neural network:
A. Learning Spatial Transformations
# Conceptual representation of what the network learns internally:
def forward(obs):
# Shared feature extraction
features = encoder(obs)
# Manipulation features (relative to the base frame)
manipulation_features = extract_manipulation(features)
# Locomotion features (in absolute space)
locomotion_features = extract_locomotion(features)
# Joint prediction (considering interactions)
hand_pose = manipulation_head(manipulation_features, locomotion_features)
base_velocity = locomotion_head(locomotion_features, manipulation_features)
return [hand_pose, base_velocity]
Key point: The manipulation and locomotion heads share information and learn their interactions.
B. Learning Temporal Consistency
By preserving manipulation trajectories, the network also learns temporal consistency:
t=0: base(0, 0), hand(1, 0, 0.5), base_vel(0, 0, 0)
t=1: base(0.1, 0), hand(1.1, 0, 0.5), base_vel(0.1, 0, 0)
t=2: base(0.2, 0), hand(1.2, 0, 0.5), base_vel(0.1, 0, 0)
Learned patterns:
5. Impact of Data Structure on Learning
Correct Data Structure (preserved manipulation trajectories + added locomotion):
# Data per timestep
{
"base_pose": [x, y, yaw], # changing
"hand_pose": [x, y, z, qx, qy, qz, qw], # relative to base, preserved pattern
"base_velocity": [vx, 0, vyaw], # locomotion command
"object_pose": [x, y, z, ...] # changing
}
What the network learns:
Incorrect Data Structure (manipulation trajectories also altered):
# Data per timestep
{
"base_pose": [x, y, yaw], # changing
"hand_pose": [completely different pattern], # manipulation also changes
"base_velocity": [vx, 0, vyaw],
"object_pose": [x, y, z, ...]
}
Issues:
6. Inference Process of the Trained Network
What the trained network actually does:
# At inference time
obs = {
"current_base_pose": [1.0, 0.5, 0.1],
"object_pose": [2.0, 0.5, 0.5],
"goal_pose": [3.0, 1.0, 0.0],
"obstacle_poses": [...],
}
# Policy inference
action = policy(obs)
# action = [hand_pose, hand_joints, base_velocity]
# Internally, the network is effectively doing:
# 1. "We must move towards the goal" → compute base_velocity
# 2. "We must keep holding the object while moving" → adjust hand_pose in the base frame
# 3. "When the base moves, the hand must move accordingly" → preserve relative relationship
Key point: The network generates coherent actions that jointly consider both locomotion and manipulation.
7. Why This Design Matters
A. Physical Consistency
Given real robot kinematics, when the base moves, the upper body moves with it. Preserving manipulation trajectories encodes this physical consistency in the training data.
B. Learning Efficiency
Clear patterns (preserve manipulation + add locomotion) lead to faster and more accurate learning.
C. Generalization Capability
By expressing manipulation in base-relative coordinates, the policy can reuse the same manipulation patterns across a wide range of base positions.
D. Stability Guarantees
Because the model learns patterns that maintain stable manipulation during movement, it behaves more robustly in real-world deployments.
Summary
“Preserving manipulation trajectories + adding locomotion commands” enables the neural network to learn meaningful correlations between locomotion and manipulation, express manipulation in base-relative coordinates, and maintain manipulation stability during motion. This is why joint training is more suitable than separate training for locomanipulation.
Share this post: