Practice Guide: Loading GR00T-Mimic Teleoperation Data + Annotation
Key Message
How to define subtask end points for each robot operation using teleoperation data and generate training data.
Summary
Step 1: Load Teleoperation Data
- Load robot demonstration data (e.g., GR-1) inside Isaac Sim
- Initial state: the robot remains in Idle mode
- Using the loaded demonstration data, the robot can begin task execution
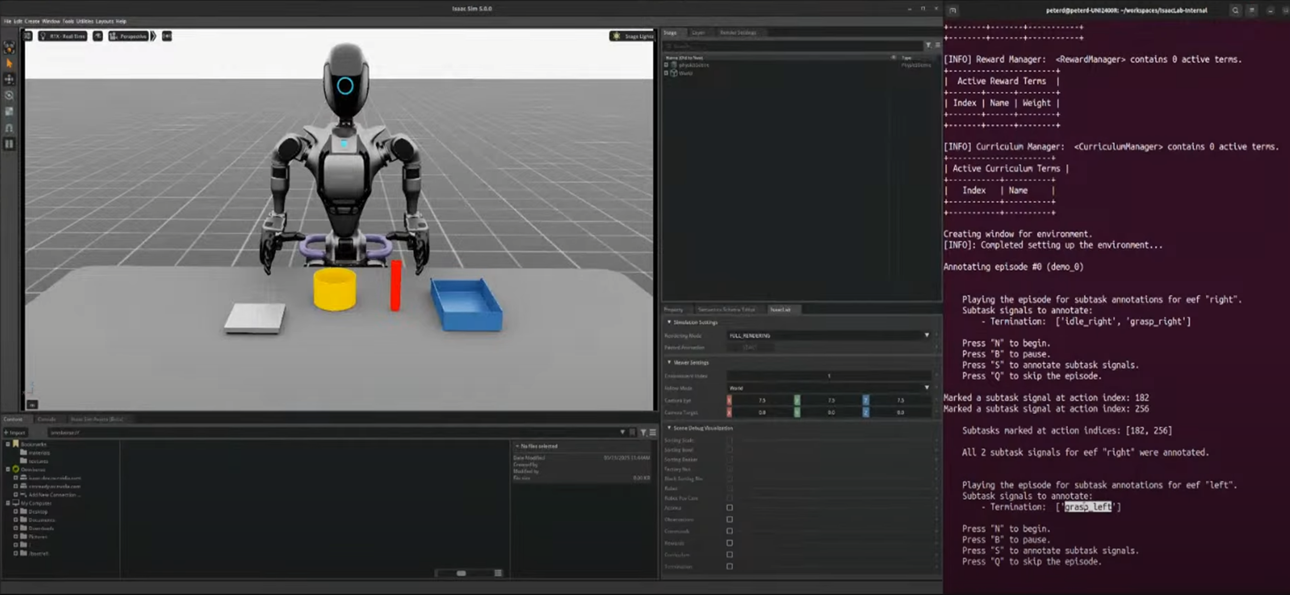
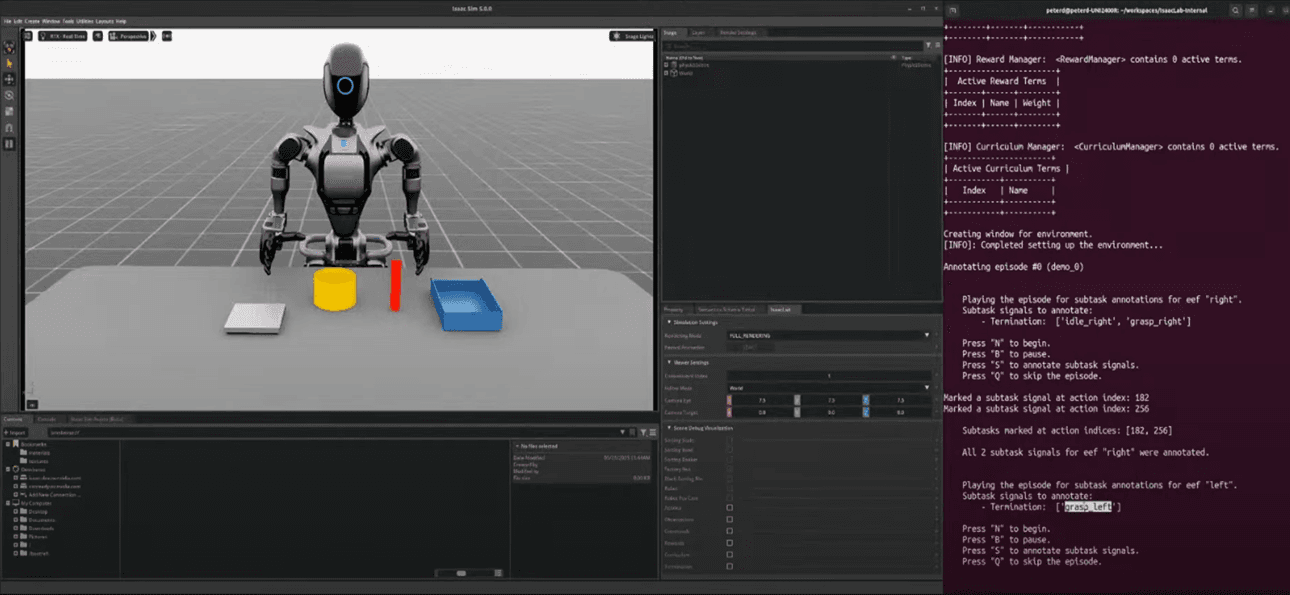
Step 2: Play Trajectory & Mark Subtask End Points
- N key: Start playback of the teleoperation trajectory
- B key: Pause playback
- S key: Mark the end point of the current subtask
- Example: Mark when the right arm completes the first task (Idle → Grasp)
- Example: Mark when the left arm completes another task (Grasp → Place)
- The end of the final task is implicitly defined (no need to manually mark)
Step 3: Example of Teleoperation
- Right Arm Task:
- Initial state: Idle
- Task: Mark the end point of the first subtask (e.g., grasping an object)
- Left Arm Task:
- Initial state: Idle
- Task: Mark the end after grasping the beaker
- The final step is automatically considered as the end of the subtask
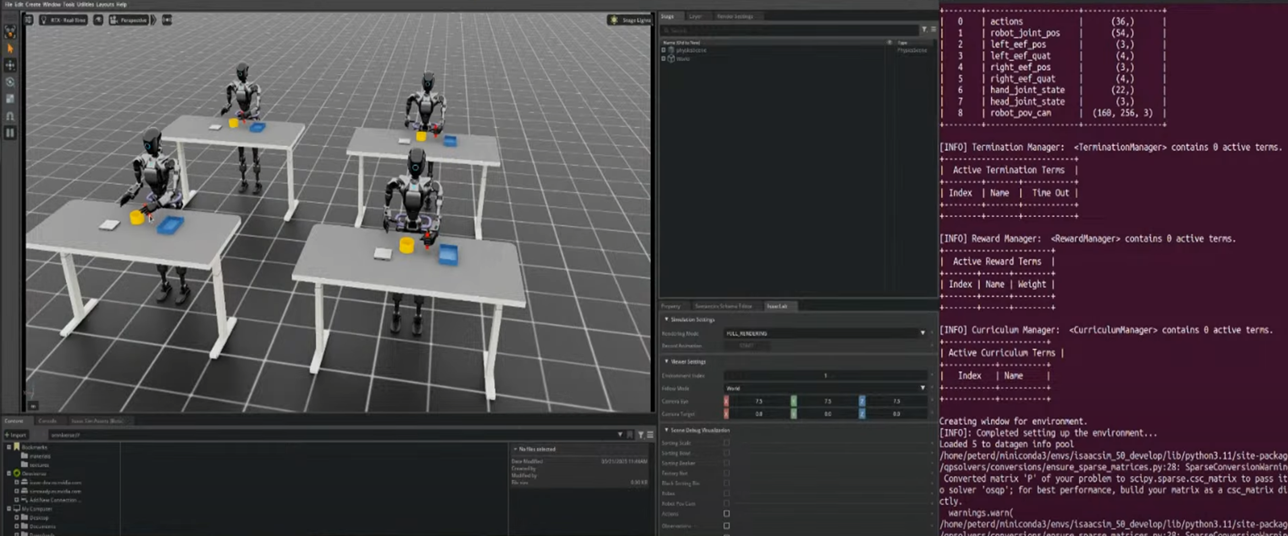
Step 4: Automated Data Generation
- Based on the marked end points, GR00T-Mimic converts data into a training-ready format
- High precision is not required; rough marking of end points is sufficient
- GR00T-Mimic uses interpolation to generate smooth and robust training trajectories
Isaac Lab Teleoperation and Imitation Learning Reference Link
https://isaac-sim.github.io/IsaacLab/main/source/overview/teleop_imitation.html
Practice Guide: GR00T-Mimic Data Generation & Playback
Key Message
How to define subtask end points using teleoperation data and generate training data.
Summary
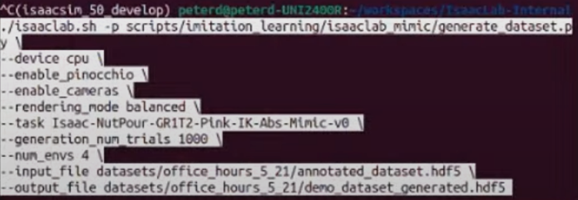
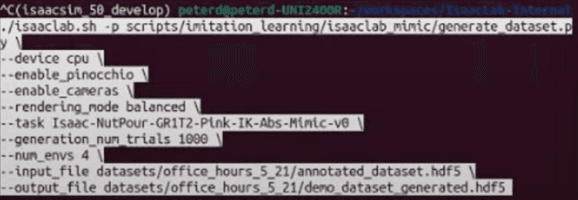
Step 1: Run Data Generation
- Execute the command below in the terminal:
- This allows data generation in 4 parallel environments
- You can change the number of parallel environments by modifying
-num_envs
Step 2: Motion Simulation
- During data generation, random action noise is added in addition to the original motion
- You may see the robot arm slightly shaking
- The trained model learns robustness under such variations and noise
- If needed, you can adjust the noise level using parameters such as
-noise_level
Step 3: Using Headless Mode
- For large-scale data generation, you can run without full Isaac Sim visualization (headless mode)
- Improves performance
- python run_data_generation.py --num_envs 100 --headless
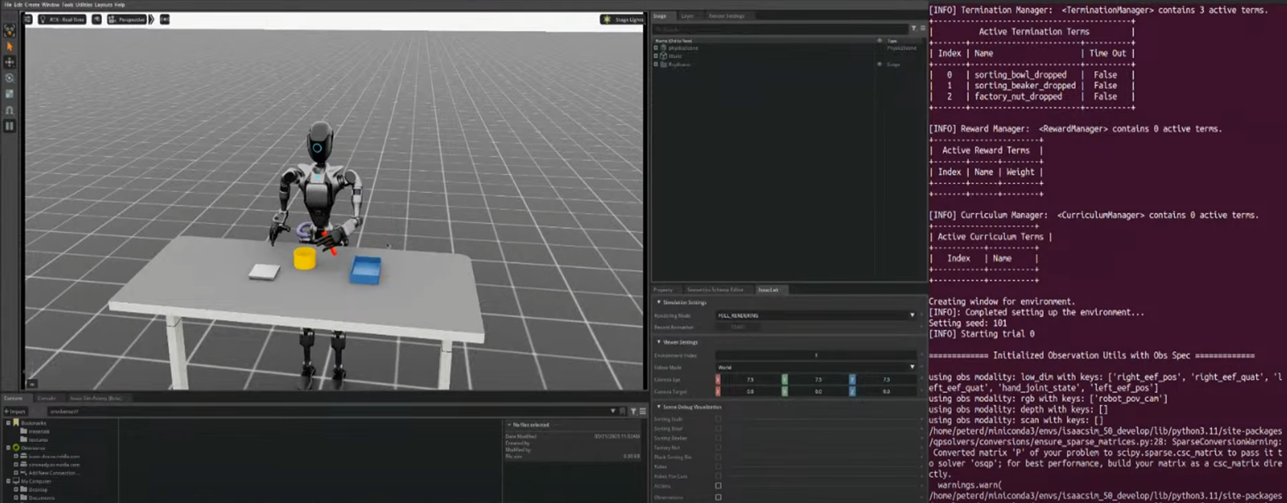
Step 4: Replay Generated Data
- You can visualize the generated data to verify quality
- Run the replay script:
- python replay_data.py --dataset_dir path/to/dataset
- You can replay both the original robot motion and the motion with action noise
- You can specify the number of parallel environments (
-num_envs)
-generation_num_trials 1000- Total number of trials (samples) to generate
- For example: generates 1000 datasets
-num_env 4- Number of parallel environments used during data generation
- Generating 1000 datasets in a single environment takes a long time
- With
-num_env 4, four datasets can be generated simultaneously → up to 4× faster
Practice Guide: GR00T-Mimic Trained Policy
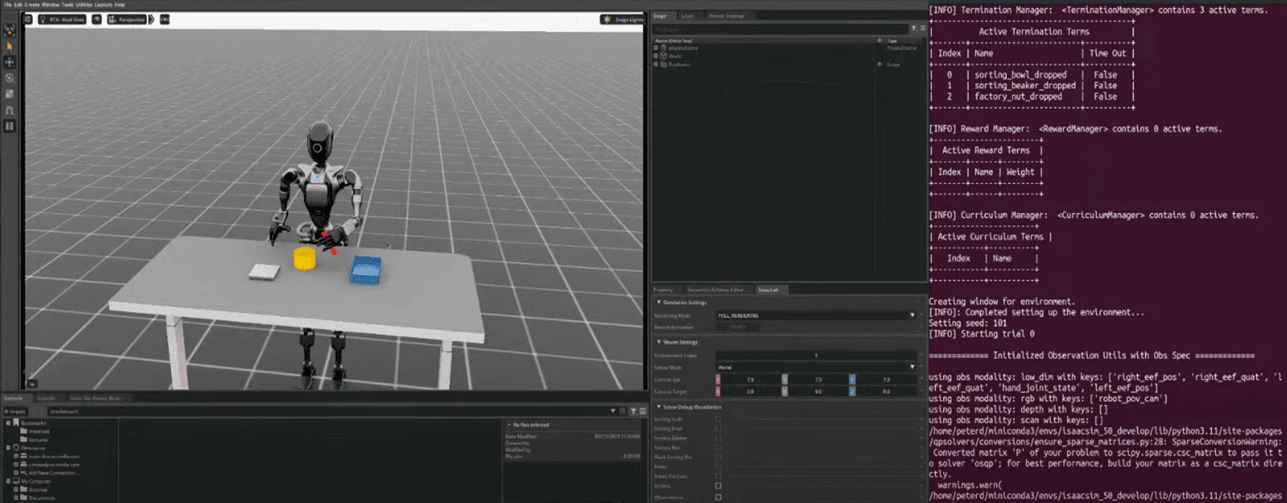
Key Message
How to define subtask end points using teleoperation data and generate training data.
Summary
Step 1: Train the Robot Policy Using Generated Data
- After collecting teleoperation demonstration data,
- Train the robot using the generated dataset (e.g., 1000 demonstrations)
- The trained policy uses an LSTM (Long Short-Term Memory) model
About the LSTM Policy
- A type of RNN well-suited for learning time-series data
- In robot control, it is useful for learning sequential actions such as:
grasp → move → place → return
- It captures temporal dependencies between consecutive actions
Step 2: Performance of the Trained Policy
- The trained policy becomes robust not only to original motion but also to randomized data
- After training, the robot shows little to no action noise (trembling) that appeared during data generation
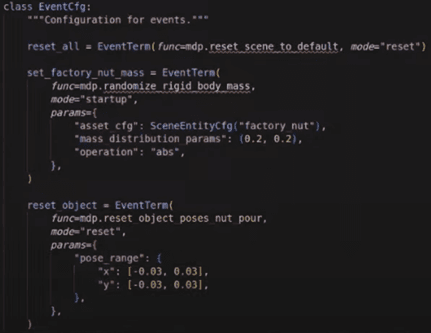
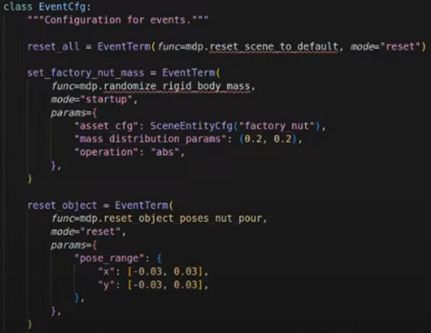
Step 3: Controlling Randomization Range
- In the training environment, the position of objects can be randomized
- Even with the same original demonstration, you can adjust the randomization range
- Example: increase the object position randomization compared to the original demo
- If the randomization range is too large:
- Training performance may degrade due to mismatch between original and generated data
- Therefore, randomization must remain within a reasonable boundary