The Robot Foundation Model is a large-scale model designed for robots to learn vision, language, and action data in an integrated manner, so they can demonstrate generalized behavioral intelligence across diverse robot forms and tasks. By mimicking humans’ “commonsense physical understanding + goal-directed behavior,” it enables transferable skills that are not restricted to a specific robot or task.

RFM uses the “physically consistent imagined worlds” produced by WFM as its training ground. Within them, it experiences thousands or tens of thousands of simulated situations and refines its behavior policies and strategies. Ultimately, RFM becomes the sum of behavioral intelligence that recognizes the physical constraints of the real world and acts proactively toward various goals.
The primary objective of RFM is to learn behavior principles that remain consistent across diverse robot forms and environments.
In other words, rather than policies fixed to a particular robot or task, it builds behavior representations that can be commonly applied to a variety of robots (arms, legs, mobile, humanoids, etc.) and tasks (manipulation, locomotion, collaboration, etc.).
Looking deeper, RFM’s ultimate goal is not “behavior itself,” but the ability to realize intent and purpose in the physical world.


RFM adopts a Perception–Reasoning–Action Loop that integrates vision, language, and action.
A robot interprets observations from the environment (Perception), understands language commands or goals (Language Reasoning), and then connects them to real motion via a behavior policy (Action).
This process is built on the following technical framework:
| Stage | Key technical basis | Description |
|---|---|---|
| Perception | Vision Transformer, 3D Point Cloud Encoder, RGB-D Fusion | Perceives scenes and object states from cameras and sensors |
| Reasoning (understanding/planning) | LLM-based Goal Parsing, Graph Transformer | Integrates language commands and visual information to produce action plans |
| Action / Policy | Diffusion Policy, Reinforcement Learning, Imitation Learning | Executes optimal behavior policies within physical constraints |
Related:GR00T N1: An Open Foundation Model for Generalist Humanoid Robots — arXiv (2025)
Related:π₀: A Vision-Language-Action Flow Model for General Robot Control — arXiv (2024)
RFM uses the physically consistent virtual worlds generated by WFM (World Foundation Model) as its training ground.

In short, if WFM predicts “what happens next,” RFM decides “what to do next.”
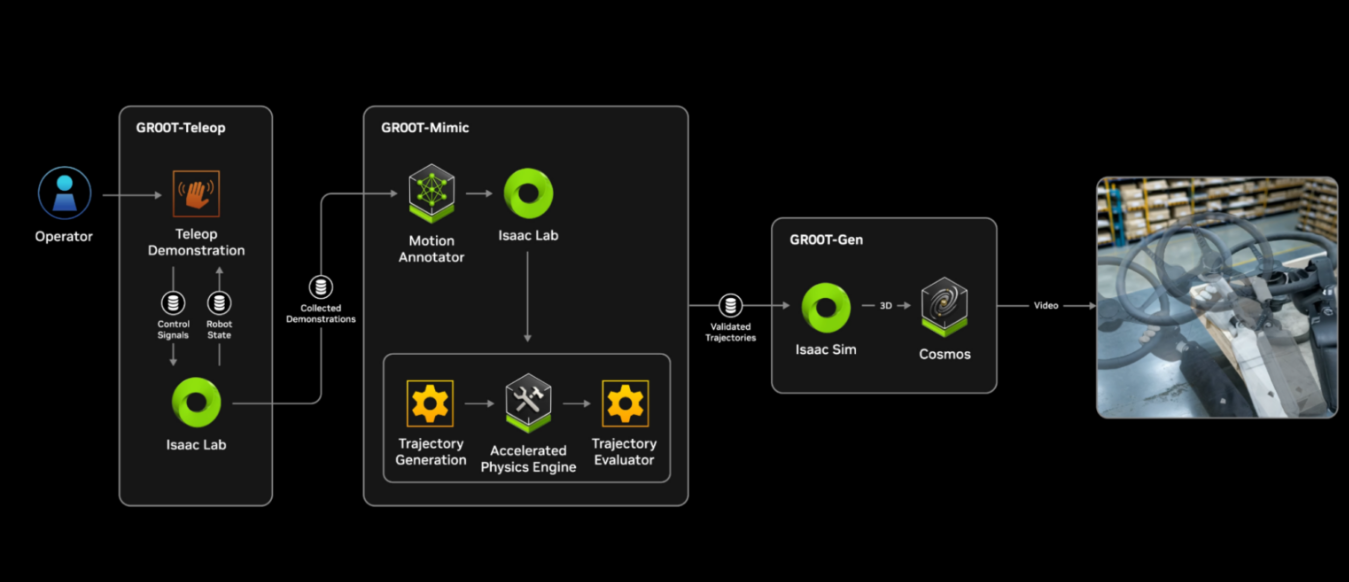
Combined, the two models form a complete Perception–Simulation–Action loop, enabling AI to transfer policies learned in simulation to real robots (Sim-to-Real). This structure aligns with the design philosophy linking NVIDIA Cosmos (WFM) and NVIDIA GR00T (RFM): Cosmos predicts and simulates the physical laws of the world, while GR00T learns robot behavior policies within that environment and transfers them to reality.
Related:NVIDIA Newsroom — “Isaac GR00T N1 and Cosmos: A Unified Physical AI Framework” (2025)
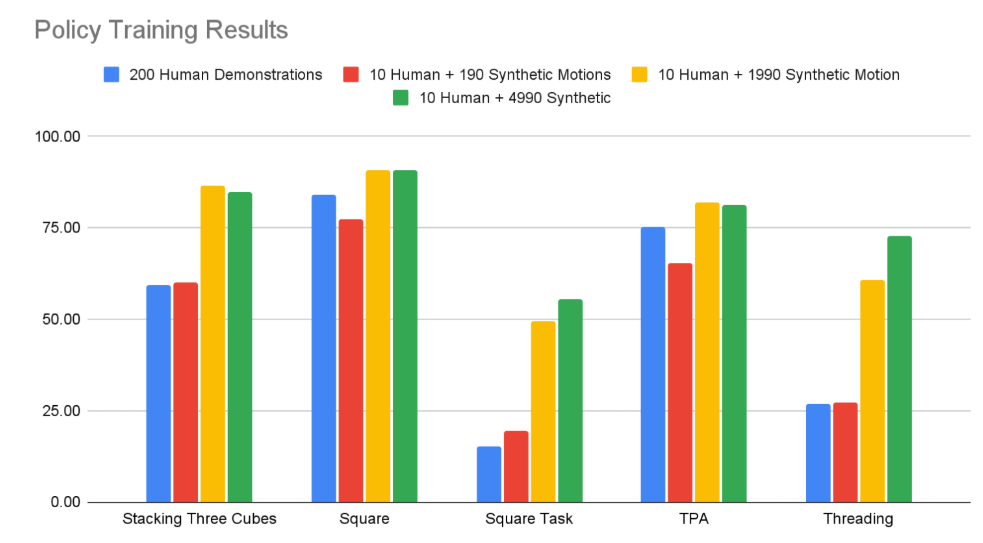
GR00T conducts large-scale imitation learning by augmenting small amounts of human demonstration data with a synthetic motion generation pipeline.
By generating thousands of synthetic motion samples, it dramatically improves policy learning performance even with limited human demonstrations.
Related:NVIDIA Developer Blog — Building a Synthetic Motion Generation Pipeline for Humanoid Robot Learning
When combined with WFM, RFM scales into an intelligent behavior policy learning model across many industries.

| Domain | Key application examples |
|---|---|
| Manufacturing & Logistics | Robot-arm assembly, pick-and-place, automated line control |
| Mobility | Autonomous robots, dynamic obstacle avoidance, indoor navigation |
| Humanoid / Service Robots | Human–robot collaboration, gesture-based interaction, environment-responsive behaviors |
| Research / Education | Robot policy research, reinforcement learning experiments, simulation validation platforms |
RFM is actively researched by multiple institutes and companies under the concept of fundamental robot models for general behavior.

| Type | Model | Organization | Key features | Representative applications |
|---|---|---|---|---|
| Behavior-integrated | GR00T N1 | NVIDIA | Vision-Language-Action structure; humanoid support | Manipulation, locomotion |
| Large-scale data | RT-X / RT-2 | DeepMind + Google Robotics | Unified training on massive behavior data | Multi-platform behaviors |
| RL-fused | π₀ (pi-zero) | Physical Intelligence | Vision-Language-Action Flow + RL | General policy learning |
| 3D manipulation | FP3 | CMU / MIT | Point-cloud-based 3D manipulation strategies | Robot arms, manipulation |
| Simulation-scaled | NVIDIA Genesis-2 | NVIDIA Research | Ultra-fast simulation engine + synthetic data generation | Expanded Sim-to-Real learning |
Related:Robotics Startup Raises $105M to Build AI Model for Robots — Genesis AI
RFM will evolve beyond merely learning robot behavior policies into a model that performs physical reasoning integrating language, vision, and action.
Future research directions include:
Integrated understanding across multiple sensor modalities such as language, vision, audio, and touch
Automatically transferring skills as robot morphology or environment changes
Continuously updating behavior policies with real-world feedback
Understanding and exploiting physical laws and causal relationships in the environment
Advancing behavior policies for collaboration, task sharing, and joint objectives among multiple robots
Share this post: