In AI development, the quality and diversity of datasets directly impact model performance. This is especially true in domains like 3D vision, robotic perception, and autonomous systems—where training data needs to reflect the complexity of real-world environments.
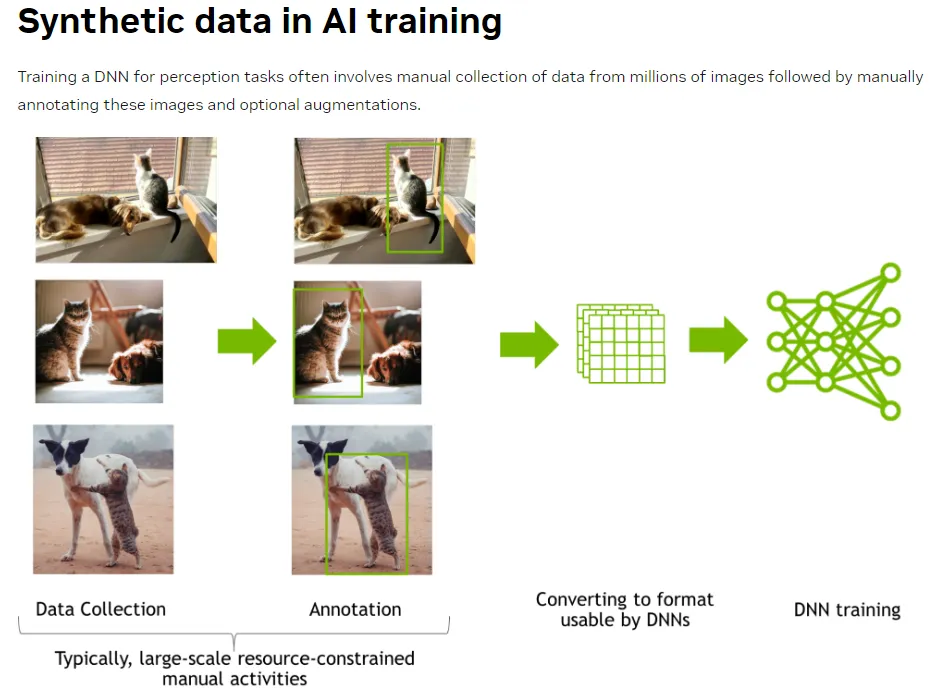
Omniverse Replicator, developed by NVIDIA, addresses this need by enabling the creation of large-scale, photorealistic synthetic datasets for AI training. In this post, we’ll walk through how to generate annotated 3D image datasets using Omniverse Replicator—from scene setup to randomized data generation.
What is Omniverse Replicator?
Omniverse Replicator is a synthetic data generation tool within the NVIDIA Omniverse ecosystem. It allows users to simulate real-world variability through randomized lighting, materials, camera perspectives, and object placement—making it ideal for AI training pipelines.
Official Docs: Omniverse Replicator Extension


With Replicator, you can generate not only realistic RGB images but also corresponding annotations like bounding boxes, segmentation maps, depth, and semantic labels, all in a single pipeline.
Environment Setup: Launching Omniverse Code
To use Replicator, you'll need to install and launch Omniverse Code via the Omniverse Launcher.
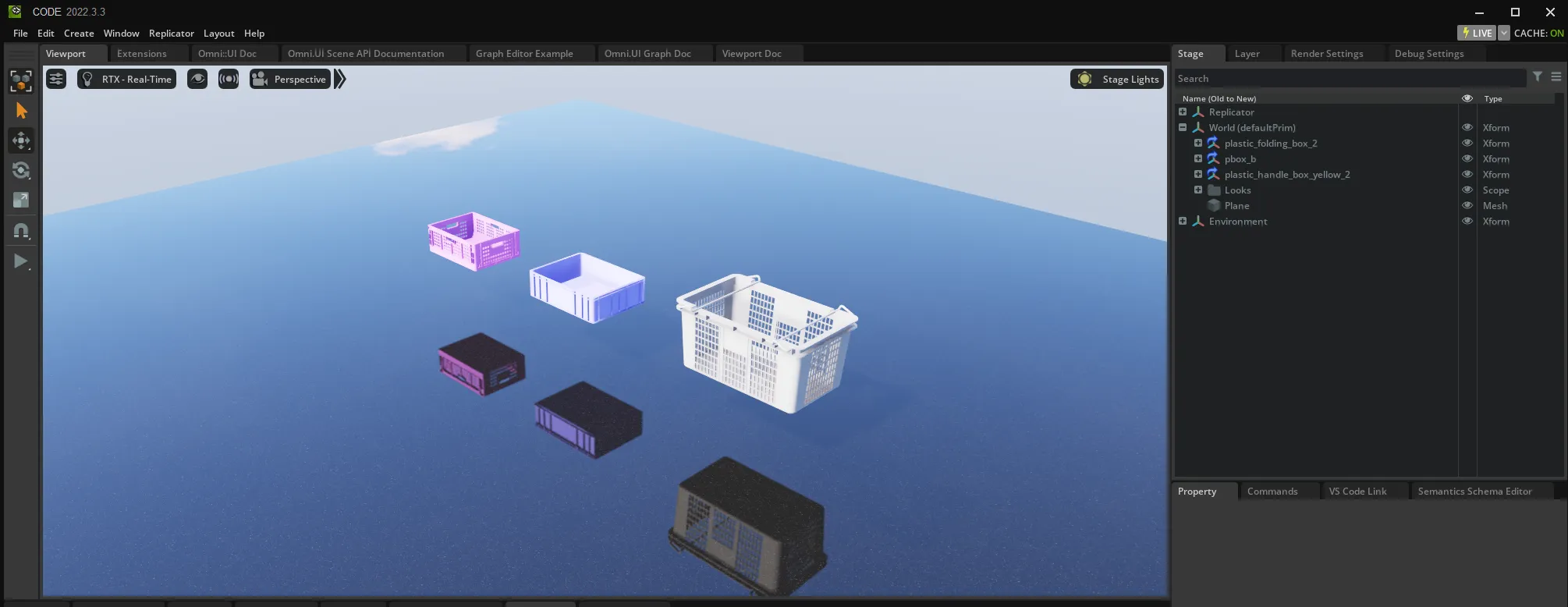
Within Omniverse Code, you can build 3D scenes and customize synthetic data generation logic using Python extensions.
To begin coding custom extensions, you can connect Visual Studio Code (VSCode) to the Omniverse environment.
Semantic Labeling: Assigning Classes to Objects
A key part of synthetic data generation is semantic annotation.
Using the Semantics Schema Editor extension in Omniverse Code, you can assign class labels to 3D objects in your scene.
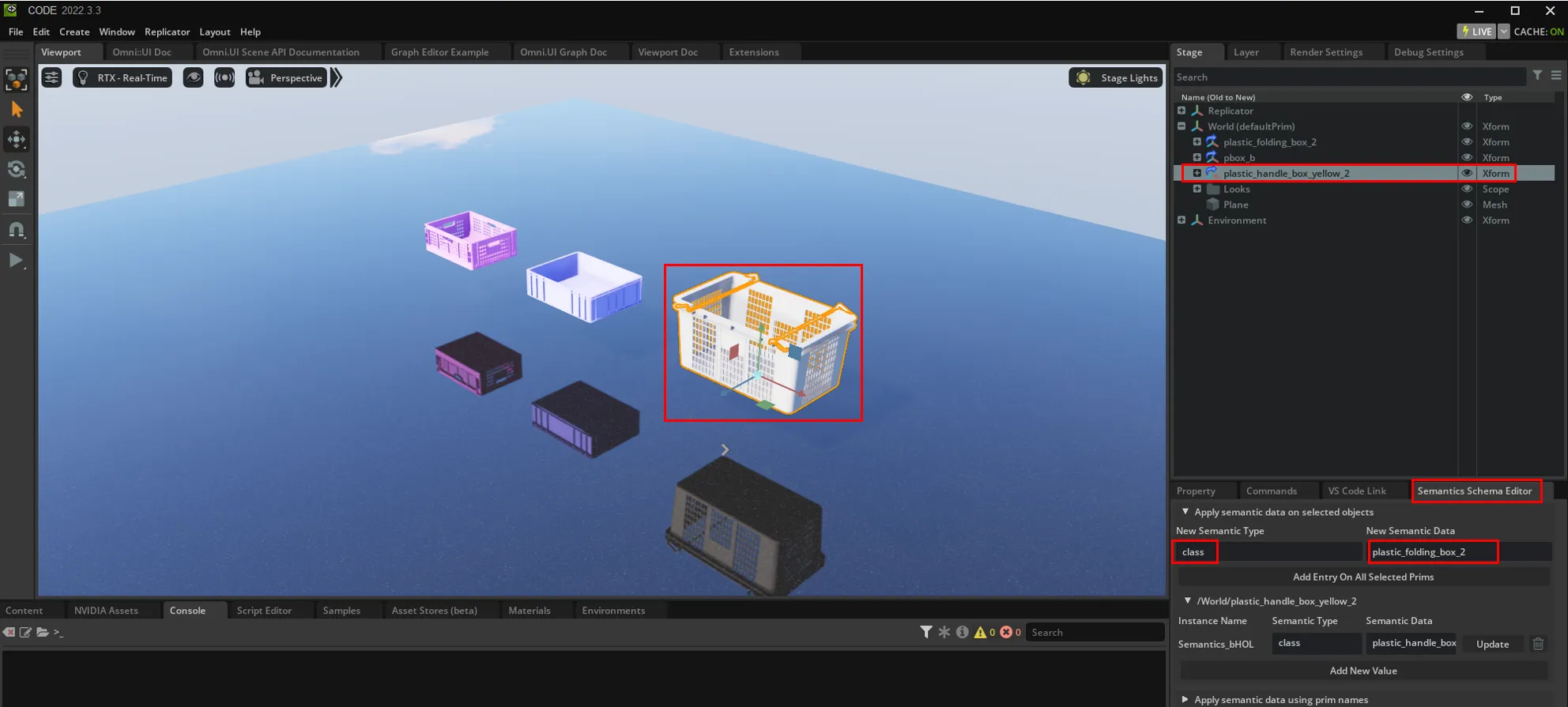
For example:
classplastic_folding_box_2, metal_box, wooden_cube, etc.Each object is identified by its Prim path, allowing Replicator to auto-generate annotations during rendering.
Setting Up Cameras and Lighting
You can freely place multiple cameras and configure lighting to simulate different viewpoints and environmental conditions.

Defining Randomizers for Object Variation
To ensure dataset diversity, you can define randomizer functions that change the position, rotation, and color of scene objects.

You can also randomize lighting, dome textures, camera angles, and more.
Generating and Saving the Dataset
Finally, you define how many frames to render and where to save the output images and labels.

This code generates 100 RGB images with corresponding annotations in the specified output directory.
Visualizing the Output
Once the generation process is complete, you can browse the saved .png images and verify annotations such as bounding boxes and segmentation labels. These synthetic datasets can now be directly used to train or validate AI models.
Final Thoughts
Omniverse Replicator is a powerful tool for creating large, realistic, and fully annotated synthetic datasets. It eliminates the need for manual image collection and labeling, making it a great asset for any AI team working on 3D perception, robotics, or simulation-based training.
From lighting to object behavior and semantic tagging, everything can be automated within the same environment. This enables rapid iteration, reproducibility, and scalable dataset creation for high-performance AI development.
Share this post: