World Foundation Model (WFM) is a large-scale model that models, predicts, and generates real-world states and changes as sequences from diverse inputs such as text, images, and video.

WFM is used for synthetic data generation and environment prediction in Physical-AI domains such as robotics and autonomous driving via physical simulation (e.g., NVIDIA Cosmos). This line of work represents the “World-as-Physics” direction, incorporating real sensors, robot actions, and autonomous-driving environments.

Meanwhile, DeepMind’s Genie 3 and OpenAI’s Sora2 learn not only physical rules of the world but also visual causality, cognitive patterns, and linguistic context—the “World-as-Perception / Understanding” family of WFM.
These models simulate environmental changes from text or video inputs alone and train agents to interpret situations cognitively.
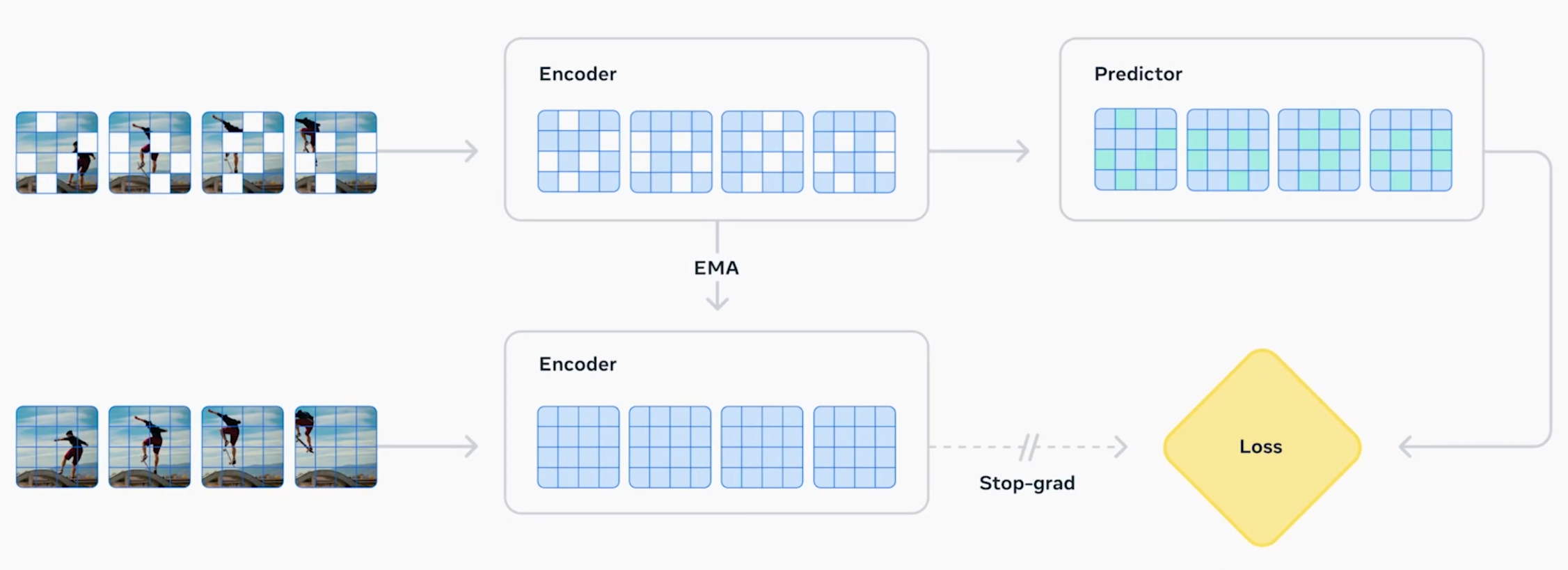
Meta V-JEPA 2 is a self-supervised video model that masks parts of frames and predicts future scenes. By inferring spatial and temporal patterns, it improves both scene understanding and action planning—representing the “World-as-Prediction / Understanding” direction within WFM.
| Category | Description |
|---|---|
| Core Concept | A WFM is a “general-purpose model that understands and predicts the world as a unit,” learning structure at the visual, linguistic, and cognitive (world understanding) levels, not only the physical environment. |
| Primary Goal | To simulate, predict, and reconstruct world states so AI can perform contextual world modeling. |
| Applications | Extends beyond robotics/autonomy to vision-language models, AI agents (reasoning), and generative world creation (GenAI). |
| Technical Base | Vision Transformers, Diffusion, Video Generation, World-Model Learning (Dreamer, PlaNet, Genie family), etc. |
| Type | Name | Traits / Description | Link |
|---|---|---|---|
| Platform / Integrated WFM | NVIDIA Cosmos | WFM platform for Physical-AI with synthetic data generation and world prediction. Integrates with Omniverse to support data generation for robotics, autonomy, and simulation. | NVIDIA Newsroom |
| World-generation | DeepMind Genie 3 | Generates interactive worlds in real time from a single line of text. A flagship generative approach to world models. | DeepMind Blog |
| World-generation | OpenAI Sora2 | Produces high-resolution, physically consistent videos from text prompts. | OpenAI Sora |
| Prediction / Understanding | Meta V-JEPA 2 | Self-supervised video model for scene prediction and planning—world understanding oriented. | Meta AI Blog |
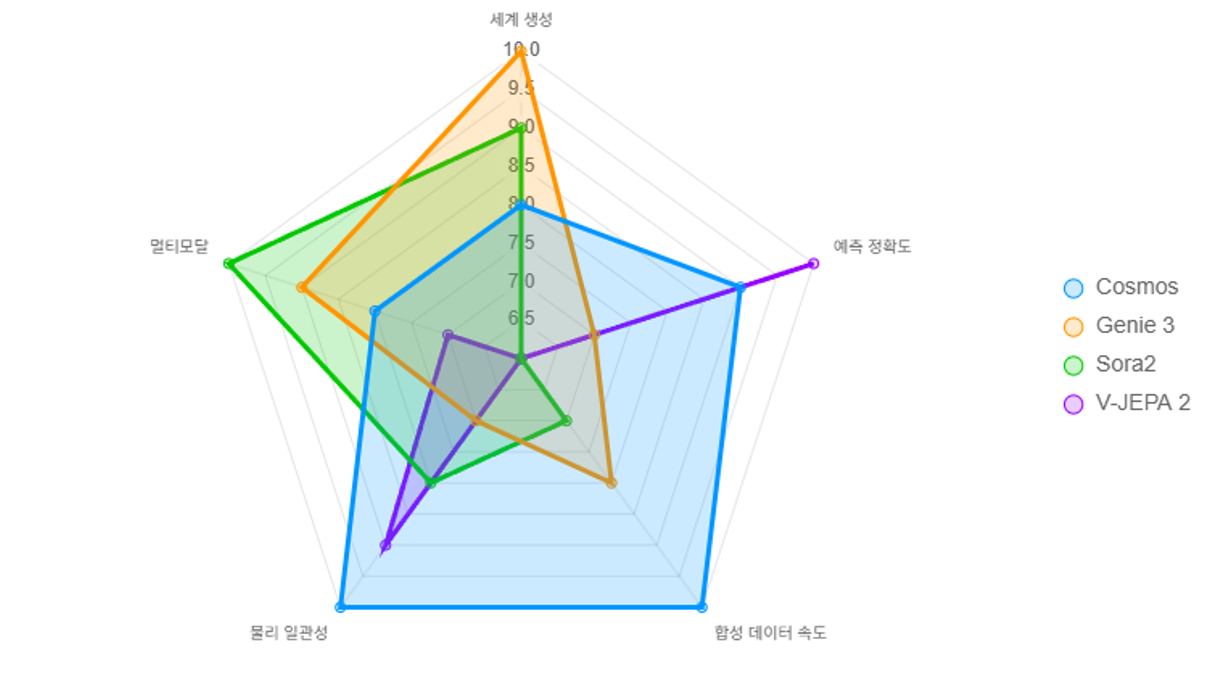
Side-by-Side Snapshot (2025, official benchmarks)
A WFM is more than a video generator.

It integrates generation + understanding + prediction + synthetic-data provision. This definition is also reflected in NVIDIA’s Cosmos documentation.
Reference:NVIDIA Announces Major Release of Cosmos World Foundation Models— NVIDIA Newsroom
WFM and RFM (Robot Foundation Model) have distinct roles:
This role split is stated in the Cosmos paper as a “world model + policy model” architecture.

The figure above (from the Cosmos paper) presents the basic WFM structure: given past observations x0:tx_{0:t}x0:t and the robot’s control inputs ctc_tct, it predicts the next world state x^t+1\hat{x}_{t+1}x^t+1.
This visually clarifies the relationship: WFM predicts the environment; RFM decides actions.
(Reference paper: Cosmos World Foundation Model Platform for Physical AI — arXiv Link: arXiv)
This separation is useful to emphasize WFM’s generation/prediction role vs. RFM’s control role.
Connection to Omniverse / NVIDIA Ecosystem
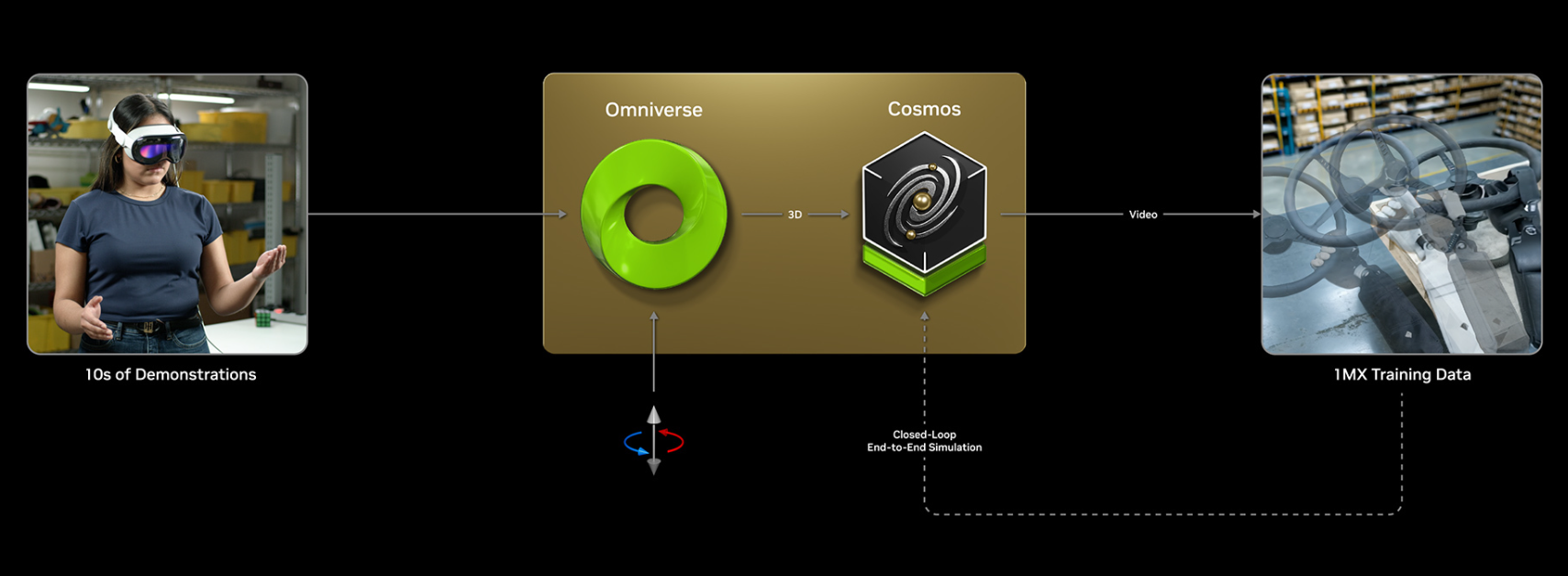
WFM—particularly NVIDIA Cosmos—ships with Omniverse libraries and supports:

Omniverse Blueprints are also reported to connect with Cosmos WFM, enabling robot-ready facilities and mass synthetic data generation.

(Article: NVIDIA Omniverse Physical AI Operating System Expands to More Industries and Partners)
WFM is not a single company’s technology but a global research trend toward AI that “understands, predicts, and generates the world.” Beyond physics-centric WFM, the field expands to cognitive, visual, and language-based world modeling.
1) World-as-Generation (world creation-centric)
| Model | Organization | Core Idea | Representative Uses |
|---|---|---|---|
| DeepMind Genie 3 | Google DeepMind | Real-time interactive world generation at ~1080p/30fps from a single text line; self-supervised learning of visual rules and interactions. | Virtual environment simulation, video-based agent training |
| OpenAI Sora2 | OpenAI | Physically consistent scene/sequence video generation from text; learns visual causal structure of the world. | Media generation, pretraining for vision models, environment synthesis |
2. World-as-Perception / Understanding (world understanding-centric)
| Model | Organization | Core Idea | Representative Uses |
|---|---|---|---|
| Meta V-JEPA 2 | Meta AI | Self-supervised prediction of future frames with masked video; internalizes spatial/temporal causality. | Robot vision, action planning, predictive perception |
| Google VideoPoet | Google DeepMind (2025 integrated) | Multimodal world model across video, audio, and text; strengthens temporal coherence and context understanding. | Video understanding, agent prediction, narrative modeling |
3. World-as-Physics (world simulation-centric)
| Model | Organization | Core Idea | Representative Uses |
|---|---|---|---|
| NVIDIA Cosmos | NVIDIA | Physically consistent models for robotics, AV, and industrial simulation; Omniverse-based synthetic data & simulation automation. | Robot learning, physics-based Sim-to-Real, digital twins |
| PlaNet | DeepMind (+ MIT extensions) | Models environment dynamics in latent space; combined with RL to improve policy learning. | Reinforcement learning, robot control, environment modeling |
WFM spans more than visual or physical information.
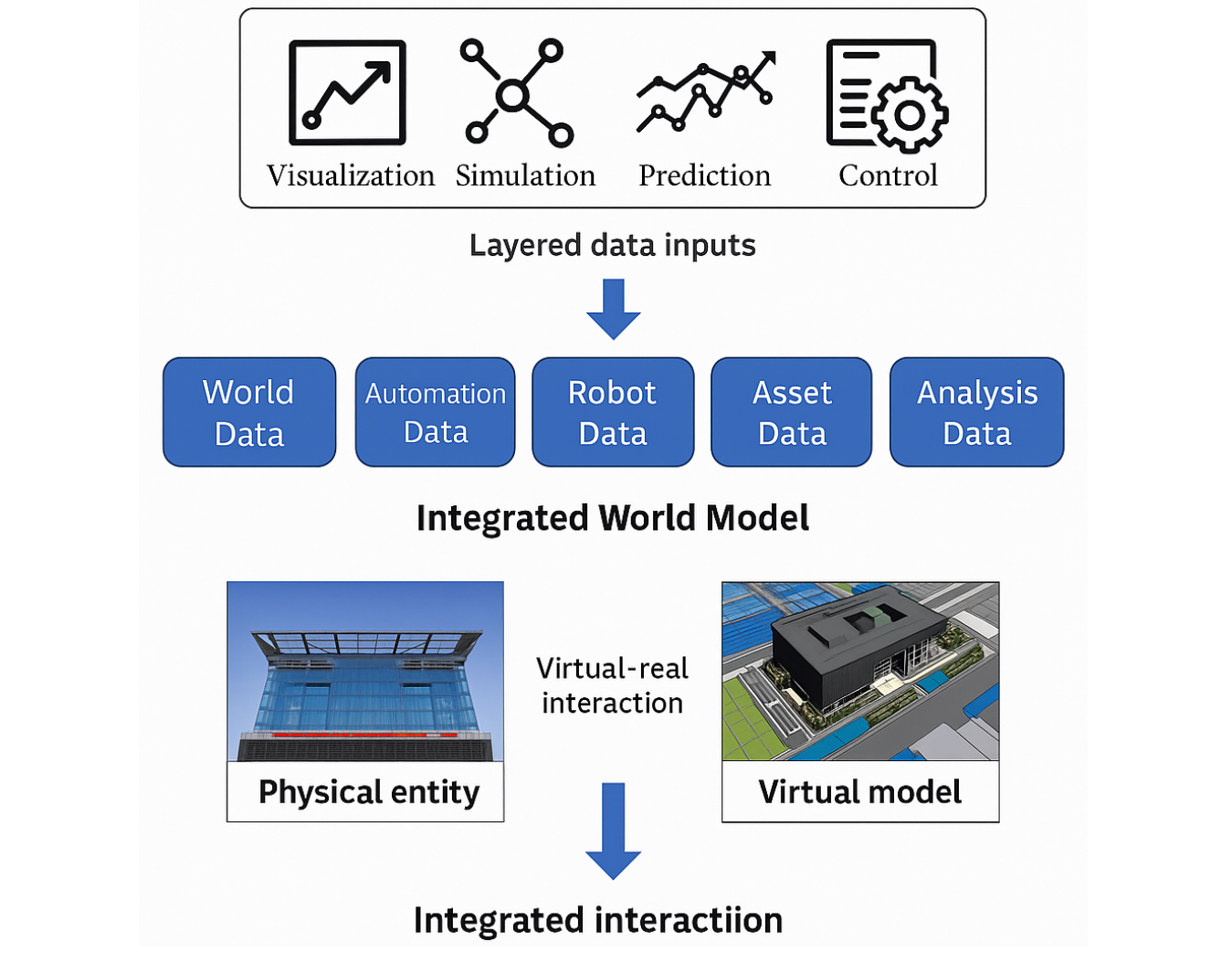
In practice, WFM integrates World / Automation / Robot / Asset / Analysis Data, evolving into an Integrated World Model that predicts world state and change.
These five data layers define WFM’s input domain. Cosmos, Genie, V-JEPA, etc., each focus on specific domains (physics, vision, cognition) while sharing the common goal of understanding and generating the world.
| Layer | Key Contents |
|---|---|
| World Data | Physical environments, visual scenes, temporal/spatial changes—the base state of the world |
| Automation Data | Processes, equipment, event sequences—procedural data from automation systems |
| Robot Data | Robot sensors, actions, control policies, behavior logs—agent experience data |
| Asset Data | Equipment/facility states, maintenance, utilization—linked to digital twins |
| Analysis Data | Integrated insights derived from the above, fed back into model training |
This layered structure forms the input foundation for WFM to understand and simulate the world, enabling AI to perform contextual world modeling.
Share this post: